Google AI Brain (NeurIPS 2019)
Introduction
- Unsupervised representation learning has been successful in natural language processing.
- Autoregressive (AR) language modeling and autoencoding (AE) are the most successful unsupervised pretraining objectives
AR language modeling
- estimate the probability distribution of a text corpus with an autoregressive model
- Given a text sequence , the likelihood is factorized into a forward product or a backward one .
- A parametric model (e.g. a neural network) is trained to model each conditional distribution
- only trained to encode a uni-directional context (forward or backward) therefore not effective at modeling deep bidirectional contexts.
- ELMo concatenates forward and backward language models in a shallow manner, which is not sufficient for modeling deep interactions between the two directions.
AE based pretraining
- does not perform explicit density estimation but aims to reconstruct original data from corrupted input
- e.g. BERT (has been the state-of-the-art approach): certain portion of tokens are replaced by a special symbol
[MASK]and the model is trained to recover the original tokens - since density estimation is not part of the objective, BERT is allowed to utilized bidirectional contexts for reconstruction. Results in improved performance compared to AR language modeling
- however, artificial symbols like
[MASK]are absent from real data and finetuning time (while the model sort of expects it), resulting in a pretrain-finetune discrepancy. - moreover, since the predicted tokens are masked, BERT is not able to model the joint probability using the product rule as in AR language modeling. I.e. BERT assumes that the masked tokens are independent given the unmasked ones. This is an oversimplification, as high-order, long-range dependency is prevalent in natural language.
XLNet is a generalized autoregressive method that leverages the best of both AR language modeling and AE while avoiding their limitations:
- XLNet maximizes the expected log likelihood of a sequence w.r.t. all possible permutations of the factorization order, not only forward or backward factorization. Thanks to the permutation operation, the context for each position consists of tokens from both left and right. In expectation, each position learns to utilize contextual information from all positions (thus it captures bidirectional context).
- XLNet does not rely on data corruption. Hence, no pretrain-finetune discrepancy.
- Uses the product rule for factorizing the joint probability of the predicted tokens, eliminating the independence assumption made in BERT
- integrates the segment recurrence mechanism and relative encoding scheme of Transformer-XL (improves performance for tasks involving longer text sequences)
Proposed method
Background
Given a text sequence , AR language modeling performs pretraining by maximizing the likelihood under the forward autoregressive factorization:
where is a context representation produced by neural models such as RNNs or Transformers and denotes the embedding of .
In comparison, BERT is based on denoising auto-encoding. Given , BERT constructs a corrupted version by randomly setting a portion of tokens to a special symbol [MASK]. Let the masked tokens be . The training objective is to reconstruct from .
where indicates is masked and is a Transformer that maps a length- sequence into a sequence of hidden vectors
Pros and cons of the two pretraining objectives:
- Independence assumption: BERT factorizes the joint conditional probability based on an independence assumption that all masked tokens are separately constructed (hence the sign): the total probability of the assignment is the product of the probabilities of individual assignments (they're not conditioned on each other) ( for non-masked tokens before reconstructing it is trivial)
- Input noise: artificial symbols like
[MASK]used in BERT never occur in downstream tasks, which creates a pretrain-finetune discrepancy. - Context dependency: the AR representation is only conditioned on the tokens up to position (left tokens), while the BERT representation has access to the contextual information on both sides.
Objective: Permutation Language Modeling
Borrowing ideas from orderless NADE.
For a sequence of length , there are different orders to perform a valid autoregressive factorization. Let be the set of all possible permutations of length . The permutation language modeling objective can be expressed as follows:
In expectation, has seen every possible element in the sequence (hence capture bidirectional context).\
Moreover, as this objective fits into the AR framework, it avoids the independence assumption and the pretrain-finetune discrepancy.
we only permute the factorization order, not the sequence order. I.e. we use the original positional encodings and rely on a proper attention mask in Transformers to achieve the desired permutation. This choice is necessary, since the model will only encounter text sequences with the natural order during finetuning.
Architecture: Two-Stream Self-Attention for Target-Aware Representations
Naive implementation with the standard Transformer parameterization may not work. Why? Assume we parameterize the next-token distribution using the standard Softmax formulation, i.e.
where denotes the hidden representation of produced by the shared Transformer network after proper masking. Now, notice that the representation does not depend on which position it will predict, i.e., the value of . Consequently, the same distribution is predicted regardless of the target position, which is not able to learn useful representations.
Why? Let's consider two different permutations and satisfying: but . Then:
Effectively, two different target positions and share exactly the same model prediction.
Therefore, we re-parameterize the next-token distribution to be target position aware:
where is a type of representations that also takes the target position as input.
Two sets of hidden representation instead of one:
- content representation (abbr. ) serves the role of the standard hidden states in Transformer. Encodes both the context and itself. Initialized to the corresponding word embedding, i.e.
- query representation (abbr. ) only has access to contextual information and the position but not the content . Initialized with trainable vector, i.e. .
Note: the standard self-attention in the Transformer is allowed to have access to the content of the position it is trying to predict, because in the encoder-decoder architecture (as opposed to language modeling), we are trying to predict the content of the target sequence, not the source sequence (thus, the target value of a certain position might depend on the source value at this position too).
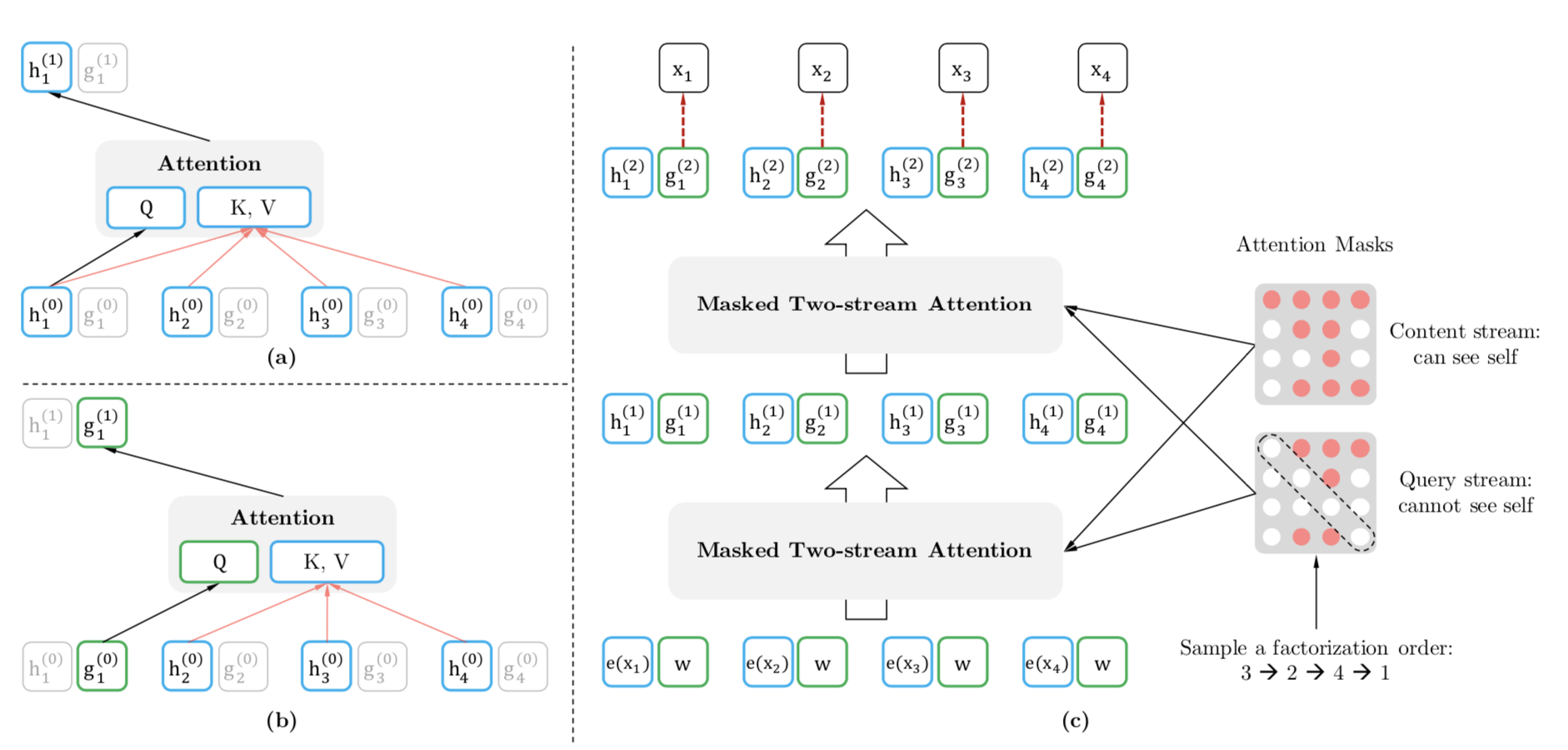 a): content stream attention (same as standard self-attention)
a): content stream attention (same as standard self-attention)
b): query stream attention (does not hav access to information about the content )
c): permutation language modeling training with two-stream two_stream_self_attention
For each self-attention layer , the two streams of representations are updated with a shared set of parameters as follows:
The reason we need the content stream attention is because for positions , we need to encode the context (which should be allowed to attend itself, i.e. not mask the diagonal).
Note: implementation details such as multi-head attention, residual connection, layer normalization and position-wise feed-forward as used in Transformer(-XL) are omitted. Refer to appendix A.2 in the original paper.
Finally, we can use the last-layer query representation to compute the next-token distribution.
Question: masking the attention matrix to fit a particular permutation of the input sequence, over all permutations; doesn't it amount to NOT masking the attention matrix at all? By not masking, one token would be able to get attention from all other tokens in the sequence, as opposed to the ones that fit the permuation order (albeit taken over all permutations).
Partial Prediction
Permutation causes slow convergence. To reduce the optimization difficulty, we choose to only predict the last tokens in a factorization order. Formally, we split into a non-target subsequence and a target subsequence where is the cutting point. The objective is to maximize the log-likelihood of the target subsequence conditioned on the non-target subsequence, i.e.:
A hyperparameter is used such that about tokens are selected for predictions, i.e. . For unselected tokens, their query representations need not be computed, which saves speed and memory.
Incorporating Ideas from Transformer-XL
Transformer-XL is the state-of-the-art AR language model. We integrate relative positional encoding (straightforward) and segment recurrence mechanism, which we discuss now.
Without loss of generality, suppose we have two segments taken from a long sequence ; i.e. and with permutations and respectively. We process the first segment based on permutation and cache the obtained content representations for each layer . Then for the next segment , the attention updae with memory can be written as:
Positional encodings only depend on the actual positions in the original sequence. Thus, the above attention update is independent of once the representations are obtained. In expectation, the model learns to utilize the memory over all factorization orders of the last segment. Query stream can be computed in the same way.
Modeling Multiple Segments
Many downstream tasks have multiple input segments, e.g. a question and a context paragraph in question answering. During the pretraining phase, following BERT, we randomly sample two segments (either from the same context or not) and treat the concatenation of two segments as one sequence to perform permutation language modeling. The input is: [CLS, A, SEP, B, SEP] (where SEP and CLS are two special symbols, and A and B are the two segments).
However, XLNet does not use the objective of next sentence prediction.
Relative Segment Encoding (on top of relative positional encoding)
BERT adds an absolute segment embedding to the word embedding at each position.
We extend the idea of relative encoding from Transformer-XL to also encode segments. Given a pair of positions and in the sequence. If and are from the same segment, we use a segment encoding or otherwise where and are learnable model parameters for each attention head. I.e. we only consider whether two positions are within the same segment, as opposed to considering which specific segment they are from. When attends to , the segment encoding is used to compute an attention weight where is the query vector as in a standard attention operation, a learnable head-specific bias vector. is then added to the normal attention weight.
Benefits or using relative segment encodings:
- inductive bias of relative encodings improves generalization
- opens the possibility of finetuning on tasks that have more than two input segments (not possible using absolute segment encodings)
Experiments
Comparison with BERT
XLNet outperforms BERT by a sizable margin on a wide spectrum of problems including GLUE language understanding tasks, reading comprehension tasks like SQuAD and RACE, text classification tasks such as Yelp and IMDB, and the ClueWeb09-B document ranking task.
Some attention patterns appear only in XLNet. They involve the relative positions rather than the absolute ones and are likely enabled by the "relative attention" mechanism in XLNet (see appendix A.6)
Comparison with RoBERTa
XLNet outperforms RoBERTa on reading comprehension and document ranking (RACE), question answering (SQuAD2.0), text classification (IMDB, Yelp, ...) and natural language understanding (GLUE).
Ablation Study
- effectiveness ot he permutation language modeling alone (compared to denoising auto-encoding objective used by BERT)
- importance of using Transformer-XL as the backbone
- necessity of some implementation details including span-based prediction; bidirectional input pipeline, and next-sentence prediction