paper (2015)
- Used as backbone for stable diffusion.
- Originally designed for image segmentation: a class label is assigned to each pixel.
- Leveraging data augmentation using elastic deformations, it needs few annotated images (30) to achieve best performance on biomedical segmentation (as of 2015) and has a training time of 10 hours on a NVidia Titan GPU (6 GB).
- It uses a contracting path to capture context and a symmetric, expanding path for precise localization.
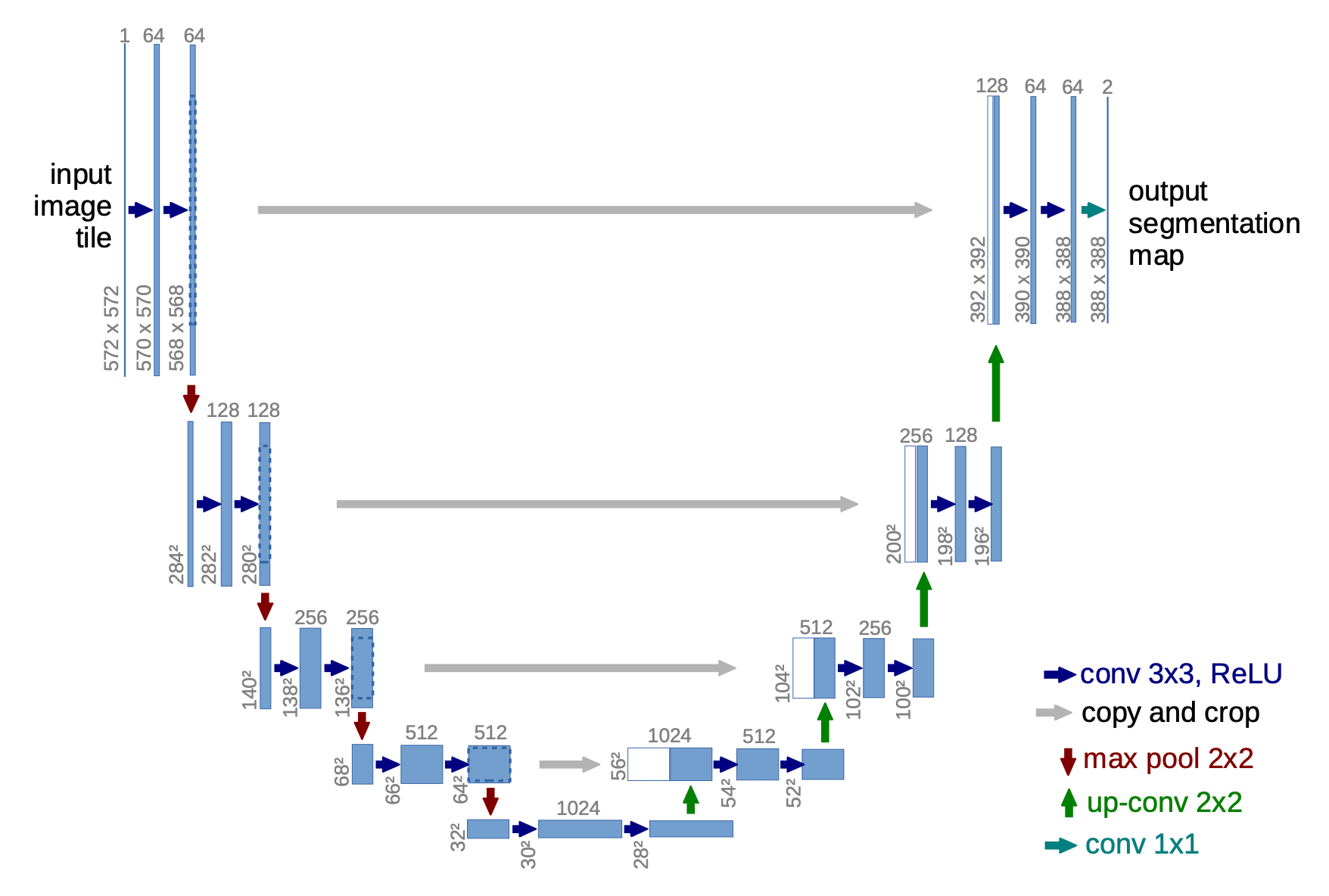
Architecture
For a recap on convolutions and up-convolutions, see the last section.
The architecture consists in:
- a contracting path (left side) is a typical convolutional network: repeated application of two unpadded convolutions, followed by ReLU and max-pooling with stride for downsampling. The number of feature channels is doubled at each convolution step, this ensures that as resolution decreases, the feature space's information capacity grows, avoiding bottlenecks.
- an expanding path (right side): every step consists of an upsampling of the feature map followed by a convolution ("up-convolution") that halves the number of feature channels, a concatenation with the cropped feature map from the contracting path and two convolutions, each followed by a ReLU. Cropping is necessary due to the loss of border pixels in every convolution.
- final layer: convolution is used to map each 64-component feature vector to the desired number of classes.
- There are no fully-connected layer in the architecture.
The loss function is the cross-entropy with respect to the soft-max over the classes for each pixel.
where:
- is some weight map introduced to give some pixels more importance in the training
- is the true class of pixel , meaning is the soft-max probability of class
The weight map is pre-computed for each ground truth segmentation. The goal is to:
- compensate the different frequency of pixels within a certain class in the training set
- force the network to learn the small separation borders that we introduce between touching cells (by applying a large weight to this border). The goal is to separate touching objects of the same class.
where:
- is the weight map to balance class frequencies
- is the distance to the border of the nearest cell
- is the distance to the border of the second nearest cell
The layers are initialized such that each feature map has approximately unit variance (drawing initial weights from a Gaussian distribution with standard deviation of where is the number of incoming nodes of one neuron).
Data augmentation
We need robustness to shift and rotation invariance. Applying random elastic deformations of the training samples allow them to use very few annotated images.
Recap on convolutions and up-convolutions
Convolution Operator

A 2D convolution is described by its kernel weights and the number of channels. The above figure shows just 1 channel.
Each output channel , sums over all the input channels . If we only look at 1 output channel, there is one weight matrix for each input channel. Each weight matrix is convoluted over its respective channel and summed.
Each output channel has its own set of weight matrices.
Denoting as the input image (with multiple channels), the 4D kernel, a bias term for output channel :
The output size of depends on the kernel size, stride and dilation:

Up-convolution operator
Also referred to as "transposed convolutions" or "deconvolutions".
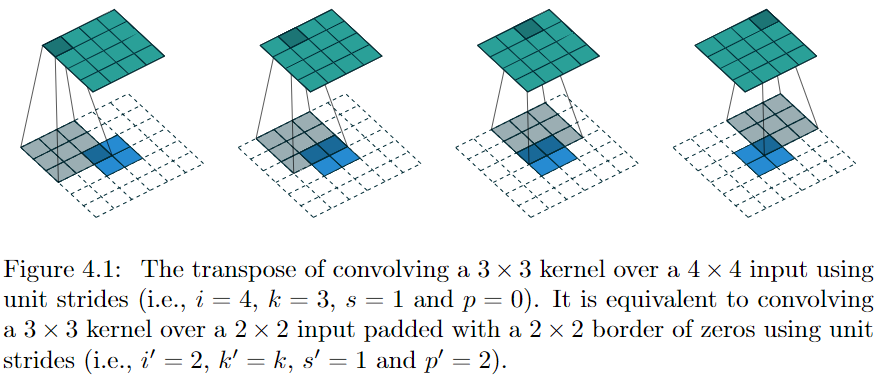
It consists in:
- padding the input feature map with zeros.
- applying a standard convolution on the padded map.