ML in research vs production: misalignment of interests
-
objective: state-of-the-art (SOTA) at the cost of complexity: e.g. ensembling is popular to win competitions but increases complexity
-
risks of complexity: more error-prone to deploy, slower to serve, harder to interpret (interpretability: allows you to detect biases and debug a model)
-
benchmarks incentivize accuracy at the expense of compactness, fairness, energy efficiency, interpretability
-
research prioritizes fast training (high throughput), production prioritizes fast inference (low latency)
-
in research/competition, not enough time spent working on the data:
-
Real-life data is streaming, shifting, sparse, imbalanced, incorrect, private, biased...
-
applications developed with the most/best data win.
-
In 2009, Google showed increasing web search latency 100 to 400 ms reduces daily number of searches per user by 0.2% to 0.6%.
In 2019, Booking.com found increasing latency by 30% in latency costs about 0.5% in conversion rates.
Majority of ML-related jobs are in productionizing ML as off-the-shelf models become more accessible and the "bigger, better" approach the research community is taking requires short-term business applications ($10+M in compute alone).
Challenges in ML production
- Data testing: is sample useful?
- Data and model versioning: see DVC
- Monitoring for data-drift: see Dessa (acquired by Square)
- Data labeling: see Snorkel
- CI/CD test: see Argo
- Deployment: see OctoML
- Model compression (e.g. to fit onto consumer devices): see Xnor.ai, acquired by Apple for ~$200M.
- Inference optimization: speed up inference time by fusing operations together, using lower precision, making a model smaller. See TensorRT
- Edge device: Hardware designed to run ML algorithms fast and cheap. Example: Coral SOM
- Privacy: GDPR-compliant (General Data Protection Regulation)? See PySyft
- Data manipulation: see Dask (parallel computation in Python, mimicking pandas)
- Data format: row-based data formats like CSV require to load all features even if using a subset of them. Columnar file formats like PARQUET and ORC are optimized for that use case.
ML systems design
Defining interface, algorithms, data, infrastructure and hardware.
Many cloud services enable autoscaling the number of machines depending on usage.
Subject matter experts (auditors, bankers, doctors, lawyers etc...) are overlooked developers of ML systems. We only think of them to label data but they are useful for: problem formulation, model evaluation, developping user interface...
Online prediction (a.k.a. HTTP prediction) vs batch prediction
-
batch prediction:
-
asynchronous
-
periodical
-
high throughput
-
processing accumulated data when you don’t need immediate results (e.g. recommendation systems)
-
-
online prediction: instantaneous (e.g. autocomplete)
Batch prediction is a workaround for when online prediction isn’t cheap enough or isn’t fast enough
Without batching, higher latency means lower throughput. With batching, higher throughput means higher latency.
Edge computing vs cloud computing
Edge computing: computation done on the edge (= on device) as opposed to cloud computing (on servers).
Cloud computing is used when ML model requires too much compute and memory to be run on device.
Disadvantages of cloud computing:
- network latency is a bigger bottleneck than inference latency.
- storing data of many users in the same place means a breach can affect many people
- servers are costly
The future of ML is online and on-device (+ see federated learning for training over edge devices).
Online learning vs offline learning
Data becomes available sequentially vs in batch. E.g. Ordinary Least Squares vs Recursive Least Squares.
Iterative process
Cycle with 6 steps:
- Project scoping (goals, evaluation criteria):
- multiple goals: loss = linear combination of multiple losses or model = linear combination of multiple models (don't need to retrain when tweaking coefficients)
- see Pareto-Based Multiobjective Machine Learning
- balance when decoupling objectives (common processing is good, coupling is bad), see multi-task learning
-
Data management (processing, control, storage)
-
ML Engineering
-
Deployment
-
Monitoring and maintenance
-
Data Science (evaluate model performance against goals, generate business insights)
Case studies
- Using Machine Learning to Predict Value of Homes On Airbnb
- Using Machine Learning to Improve Streaming Quality at Netflix
- 150 Successful Machine Learning Models: 6 Lessons Learned at Booking.com
- How we grew from 0 to 4 million women on our fashion app, with a vertical machine learning approach
- Machine Learning-Powered Search Ranking of Airbnb Experiences
- From shallow to deep learning in fraud
- Space, Time and Groceries
- Creating a Modern OCR Pipeline Using Computer Vision and Deep Learning
- Scaling Machine Learning at Uber with Michelangelo
- Spotify’s Discover Weekly: How machine learning finds your new music
Data Engineering
Better algorithms vs more data:
- Judea Pearl warns of the data-centric paradigm
- structure allows us to design systems that can learn more from less data (see Deep Learning and Innate Priors video)
- Other side: More data usually beats better algorithms
- The Bitter Lesson by Richard Sutton
- The Unreasonable Effectiveness of Data
Sources
- First party data: data you collect about your own customers
- Second party data: data that someone else collects about their customers
- Third party data: data that someone else collects about the general public
Formats
Row-based is best to access samples, continuously write transactions. Column-based is best to access features.
Examples of formats:
json, csv (row-based, access samples), parquet (column-based, access features; Hadoop, Amazon Redshift), avro (Hadoop), protobuf (TensorFlow), pickle (python, PyTorch)
CSV is text, Parquet is binary (more compact, but not human readable)
Pandas is column-based, whereas NumPy is row-based. Accessing a row in pandas is slower than in NumPy and it's the opposite for columns. See just-pandas-things
OLTP (OnLine Transaction Processing) vs. OLAP (OnLine Analytical Processing) databases.
A repository for storing structured data (processed) is called a data warehouse. A repository for storing unstructured data (raw) is called a data lake.
Stream storage: Apache Kafka, Amazon Kinesis.\
Stream processing: Apache Flink.
Having two different pipelines to process data is a common cause for bugs in ML production.
Readings:
- Uber’s Big Data Platform: 100+ Petabytes with Minute Latency
- Keystone Real-time Stream Processing Platform
- A Beginner’s Guide to Data Engineering
Learning with noisy labels
Data lineage: track where data/label comes from
- Learning with Noisy Labels
- Loss factorization, weakly supervised learning and label noise robustness
- Cost-Sensitive Learning with Noisy Labels
- Confident Learning: Estimating Uncertainty in Dataset Labels
Weak supervision
Programmatic labeling, alternative to hand labeling (expensive, linear in number of samples, non private)
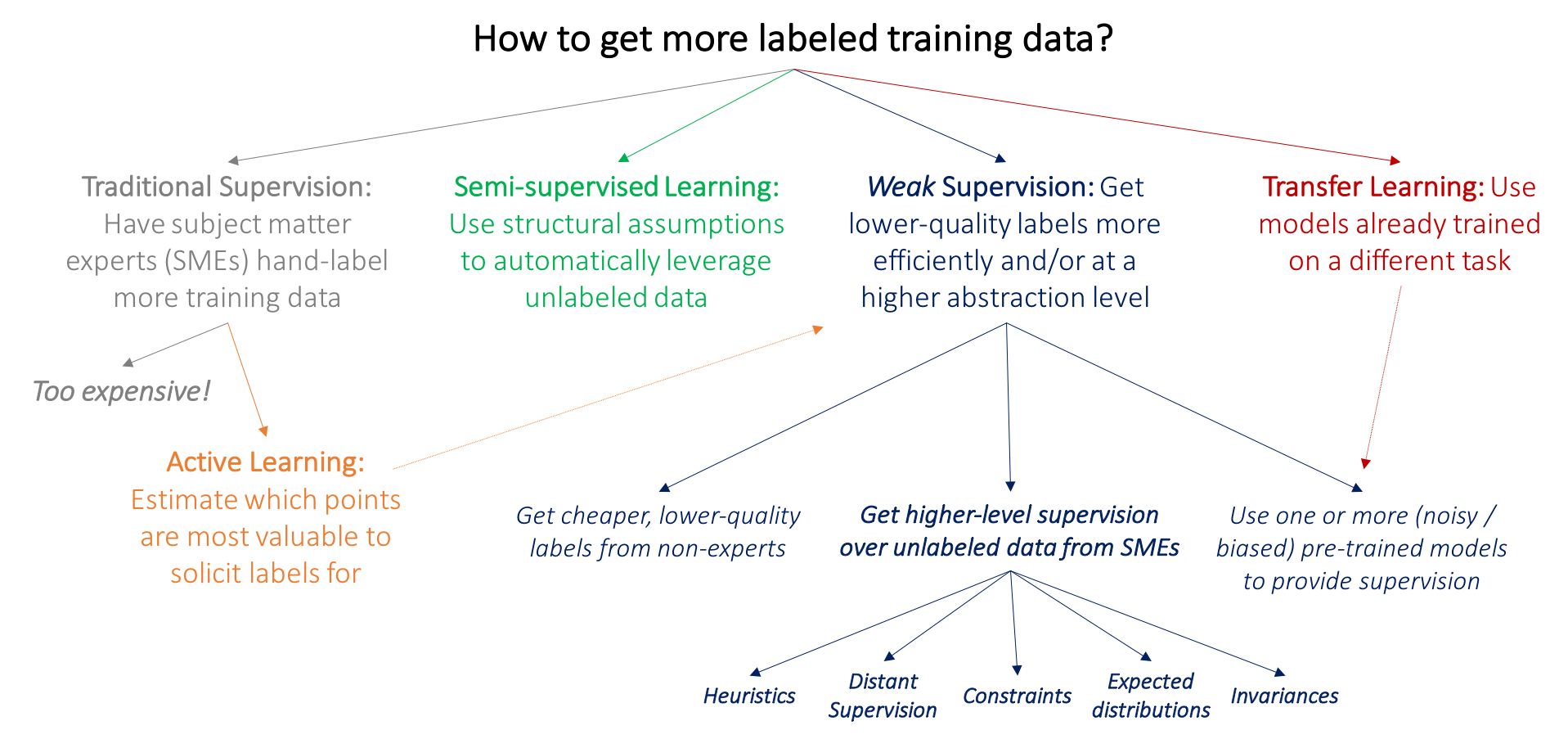
Transfer Learning
zero-shot (no example, no gradient update) vs few-shot (few examples as input, no gradient updates) vs fine-tuning
Active Learning
Model queries labels that are most helpful to its learning. See Active Learning Litterature Survey
Model development and training - part I
Sampling
Samples of real world data. Two families: non-probability sampling and random sampling.
Random sampling
Simple random sample (SRS)
Each sample has equal probability of being selected. Con: rare class is undersampled.
Stratified sampling
Divide population into groups (strata) and sample a certain percentage from each group. Challenging for multilabel class.
Weighted sampling
Each sample is given a probability of being selected. Embed subject matter expertise.
Different from sample weights: sample weights are used to weight samples in the training loss, after being selected.
Importance sampling
See Stanford CS228 Lecture Notes.
Reservoir sampling
Imagine you have to sample tweets from an incoming stream of tweets with constraints:
- you don't know how many tweets there are
- you can't fit them all in memory
- you want every tweet to have equal probability of being selected
Solution:
- first elements are put in the reservoir
- for each incoming -th element, generate random number between and .
- if , replace -th element in reservoir with -th
Each incoming -th has probability of being put in the reservoir and has a probability of of being placed at any position, given that it was sampled.
Let's say there are elements in total (we don't know ). The probability of the -th element of being put in the reservoir and staying in there (thus, in effect, probability of being sampled) once the stream has finished running is:
Each item in the population has equal probability of being sampled.
Non-probability sampling
See personal notes
No probability rule for selecting a sample. Not representative of real world data and embedded with selection bias:
- convenience sampling: (based on what is available, popular because convenient)
- snowball sampling: future samples based on existing samples
- judgment sampling: experts decide which sample to include
- quota sampling: select sample based on quotas
Class imbalance
Insufficient signal for minority class (effectively becomes few shot learning). Trivial solution (always predict majority class) can have high accuracy but is of no use.
Solutions
Note: some argue that you should not try to fix class imbalance if that's how the data is in the real world. Why?
Resampling
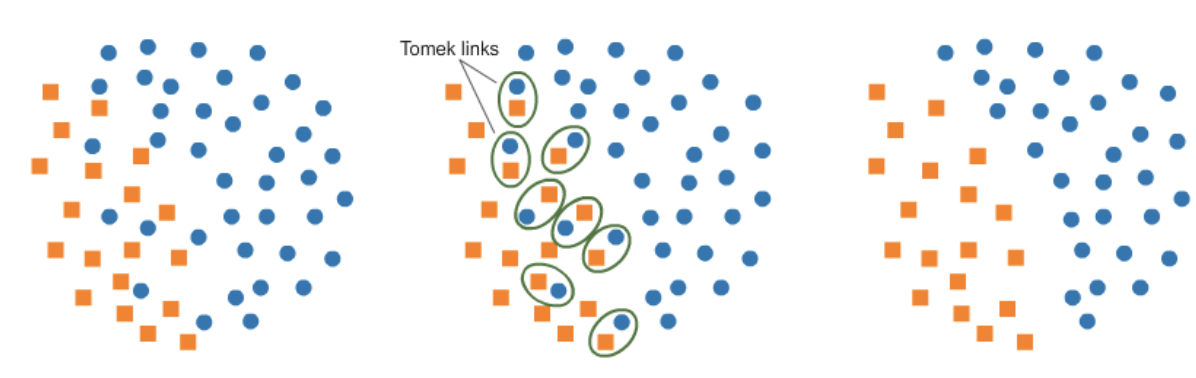
Undersampling: Tomek links
Find pairs of samples from opposite class that are close and remove the majority class. Clear decision boundary but possible under-fitting:
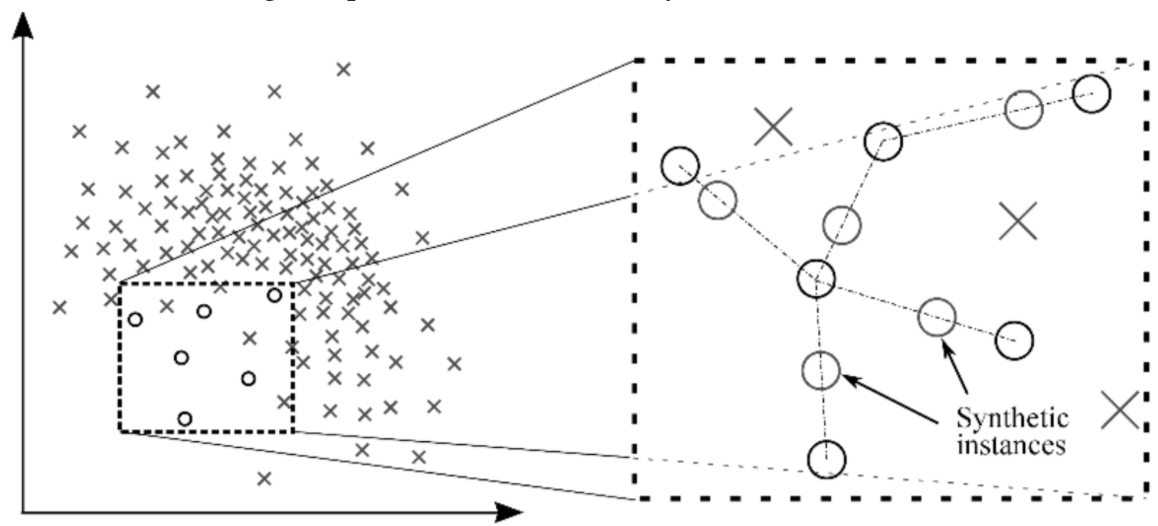
Oversampling: SMOTE (Synthetic Minority Oversampling TEchnique)
Sample convex (=linear) combinations of existing data points within the minority class.
Oversampling: Data augmentation
For CV: random cropping, flipping, erasing, etc...
Mixup (for speech and tabular data): mix X% of class A and Y% of class B. Incentivizes model to learn linear relationsips (assumption is that linear behavior reduces variance outside training set)
Loss adjustment: weight balancing
Biasing towards rare class
- Naive version: weigth is inversely proportional to cardinality of the class
- More sophisticated version: Balanced Loss Based on Effective Number of Samples
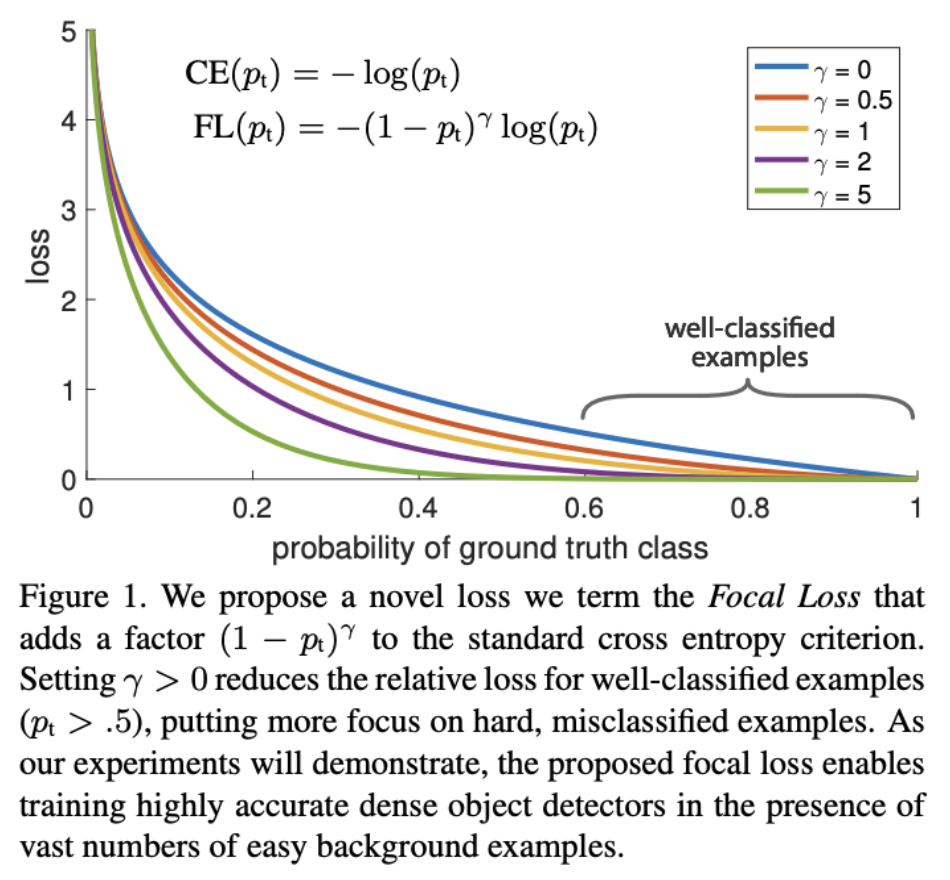
Biasing towards difficult samples
See Focal Loss
Algorithms
Ensembling methods such as boosting and bagging, together with resampling, perform well on imbalanced datasets.
Papers:
- A Review on Ensembles for the Class Imbalance Problem: Bagging-, Boosting-, and Hybrid-Based Approaches
- Solving class imbalance problem using bagging, boosting techniques, with and without using noise filtering method
Bagging (bootstrap aggregating)
Sample bootstraps with replacement and learn one model per bootstrap. If classification, final prediction is majority vote. If regression, final prediction is average.
Reduces variance (=prevents overfitting)
Boosting
Iteratively combine weak learners.
See:
- Adaboost (reweight samples and learners based on performance)
- Gradient Boosting Machine (gradient descent in function space)
- XGBoost (variant of Gradient Boosting Machine): used to be algorithm of choice for winning competitions
- LightGBM: dethroned XGBoost in competitions. Faster training for similar accuracy.
Model selection baselines
Random baseline, Most-common class, Human baseline, simple heuristic, existing solutions (APIs)
When to use deep learning in practice
- task can be reduced to generally "solved" image or text task
- "fine-tuning" an existing model instead of training a model
from scratch
- lots of data (>10k examples)
- data is balanced
- data doesn't change over time
Scaling
Larger models + more data

Need distributed training (GPT-3 would need 355 years to train on a single GPU).
- BERT (2018): 110M (Base) - 340M (Large)
- T5 (2019): 60M (Small) - 11B (Large)
- GPT-3 (2020): 125M (Small) - 75B (Large)
- Switch Transformer (2021): 1 Trillion
1B parameters at floating point 16 (fp16 = 16 bits = 2 bytes): . 175B parameters = 316.2 GB
NVIDIA A100 80GB GPU (2020): not enough memory.
Forward activations are a major source of memory usage: minibatch size x # parameters
Solution 1: gradient checkpointing: see article by OpenAI (10x larger models against +20% computation)
Solution 2: data parallelism for large batch training (each device replicates model and optimizer but sees a fraction of the batch). Communication between nodes needed to synchronize gradients (message passing interface, NVIDIA collective communications library, facebook gloo). All-reduce: every GPU sends tensors to designated manager who reduces them and sends results back to workers.
Columnar data: apache parquet (Disk), apache Arrow (in-memory)
Parallel workers: apache Spark, multiprocessing, multithreading
Libraries: Huggingface Datasets, Uber Petastorm, Tensorflow Datasets
Further readings: Exploring the limits of weakly supervised pretraining, MegatronLM: training Billion+ parameters Language Models using GPU Model Parallelism