Model Free Evaluation
- we don't know the transition probabilities and rewards
- assume infinite horizon, stationary rewards, transition probabilities and policies
In dynamic programming, we bootstrap/estimate the value of the next state value using our current estimate until convergence.
Monte-Carlo on-policy evaluation
Works for episodic environments.
-
Sample lots of episodes until termination
-
go over the episodes and keep track of:
-
: number of times we were in each step
-
: sum of total returns starting from the current step (e.g. for episode , timestep , )
-
-
For each state ,
We can also keep an incremental estimate of :
When , it gives higher weight to newer data, which helps in non-stationary settings.
Two variations:
- first-visit monte carlo (only update sate counters the first time we visit the state within the episode)
- every-visit monte carlo (more data efficient in a true Markovian setting)
Monte-Carlo off-policy evaluation
off-policy = use data taken from one policy to evaluate another
in costly or high stake situations we are not able to obtain rollouts of under the new policy.
Importance sampling
In our case , the new policy we want to evaluate and , the old policy under which the episodes were generated.
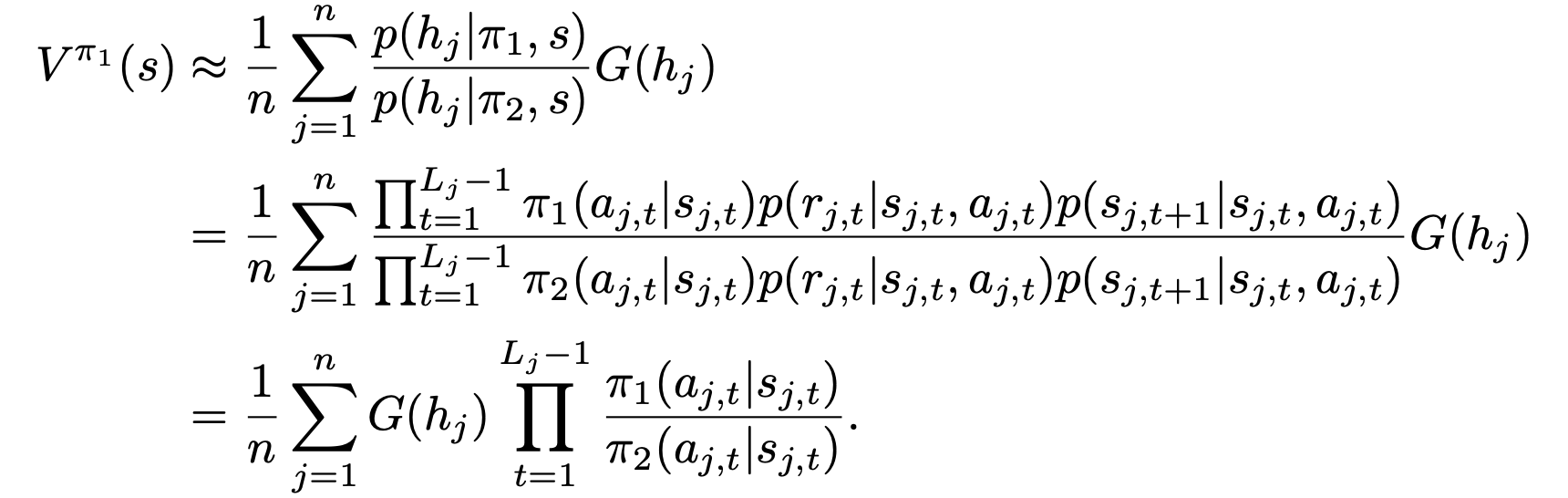
where is the total discounted sum of rewards for history .
Temporal Difference (TD) learning
Combines bootstrapping (DP) and sampling (Monte Carlo).
We bootstrap the total returns with the next state's estimate: (called the TD target).
is called the TD error.
Since we don't use the total sum of discounted rewards we don't have to wait for the episode to finish.

- the reason why we are able to backup over one timestep in DP is because of the Markov assumption. We can use incremental Monte-Carlo with in non markovian settings.
- we proved DP converges to the true value function by proving that the Bellman backup operator is a contraction
- in TD learning, we bootstrap the next state's value to get an estimate of the current state. It is thus biased towards the next state's value.
- TD learning is also less data efficient than Monte-Carlo. Since the information only comes from next state (vs the total discounted sum of rewards of the entire episode), we neet to experience an episode times ( being the length of the episode) to get the full information back to the starting state (especially impactful if high reward is experienced at the end).
Batch Monte-Carlo and TD
- Monte-Carlo batch setting: value converges value that minimizes mean squared error (since the minimizer of is )
- TD batch setting does not converge to the same value:
