Assumptions
- Markov Property:
- Finite state space:
- Stationary transition probabilities (time-independent): . We can write it as a transition probability matrix of size where .
Markov Reward Process
add:
- : reward function mapping states to rewards
- discount factor
Expected reward:
Stationary rewards assumption:
- (same state implies same reward)
- For stochastic rewards: and we have (same state, regardless of step, implies same CDF and therefore same expected reward)
Q: A condition on the CDF implies a condition on the distribution itself
A condition on the Cumulative Distribution Function (CDF) is equivalent to a condition on the distribution itself. The CDF is a representation of the probability distribution of a random variable.
The reason the CDF might be used instead of the Probability Density Function (PDF) or Probability Mass Function (PMF) is that the CDF is defined for all kinds of random variables—discrete, continuous, and mixed—while the PDF or PMF is only defined for continuous or discrete random variables, respectively.
This condition therefore implies the condition that expected rewards be constant.
- Horizon: number of time steps in each episode (finite or infinite)
- Return: sum of discounted rewards
- State value function: (expected return starting from ).
Infinite horizon (with ) + stationary rewards (stationary state value function).
Computing the state value function
Monte Carlo Simulation

Analytic solution
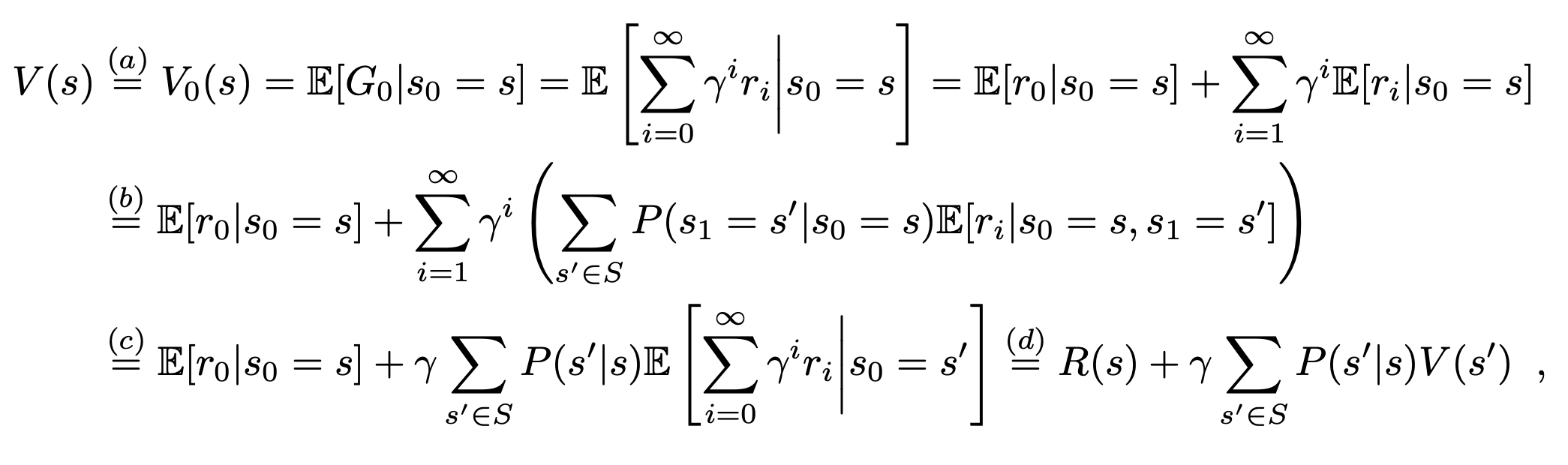
As we can write: which has the analytical solution (complexity in ).
(this assumes that we have the transition probabilities and rewards)
Dynamic Programming solution
Finite horizon:
- start with (by definition, there are no future steps to consider, so the expected sum of future rewards is zero)
- iterate back to with
Infinite horizon:
- we know must be time-independent
- start with two value function estimates and
- update estimate until (infinity norm is the component with largest absolute value) and return
- see p.8 for proof of correctness
Complexity:
Markov Decision Process
add : finite set of actions available from each state .
Stationary transition probabilities:
(where action precedes state)
Stationary rewards:
Policy: probability distribution over actions given current state. Can vary with time: (where subscript denotes timestep)
- State value function: . When horizon is infinite, state value function is stationary and
- State action value function: . Meaning we compute expected return given that we are in state and take action . With infinite horizon:
Computing state action value function for infinite horizon:
A stationary policy (i.e. ) has an equivalent markov reward process (by taking expectation over action space):
Can then use previous techniques to evaluate value function (we call it policy evaluation).
MDP control for infinite horizon
optimal iff .
For infinite horizon MDP, existence of an optimal policy implies existence of a stationary optimal policy (i.e. we only need to consider stationary policies). Intuitively, if is an optimal (non-stationary) policy, we can compute which is independent of time (because horizon is infinite), for all . By the definition of an optimal policy, we can just keep the that has the maximum state value function.
Moreover, there is an optimal deterministic policy such that for all states . We can construct it from a stationary policy:
Search for an optimal policy has been reduced to the set of deterministic stationary policies (there's possibilities).
Policy search

Brute force algo. Terminates because it checks all policies.
Policy iteration
more efficient.


Proof of correctness: https://stats.stackexchange.com/questions/272777/policy-and-value-iteration-algorithm-convergence-conditions/299950#299950
The value functions at every iteration are non-decreasing. If we cannot improve our policy further, it means:
thus:
which is the Bellman optimality equation.
Value iteration
We look for a fixed value function instead of a fixed policy.

MDP control for finite horizon
In the finite horizon state, there's an optimal deterministic policy but it is no longer stationary (at each time , the policy is different).
