Introduction
Probabilities are inherently exponentially-sized objects; need to make assumptions about their structure.
Naive Bayes assumption: conditional independence among the variables
Three major parts in this course:
-
Representation: how to specify a (tractable) model?
-
Inference: given a probabilistic model, how to determine the marginal or conditional probabilities of certain events.
-
marginal inference: what is the probability of a given variable in the model?
-
maximum a posteriori (MAP) inference: most likely assignment of variables given the data.
-
-
Learning: fitting a model to a dataset. Learning and inference are inherently linked, as inference is a key subroutine that we repeatedly call within learning algorithms.
Applications:
-
Image generation (see Radford et al.). Sampling new images from a learned probability distribution that assigns high probability to images that resemble the ones in the training set.
-
In-painting: given a patch, sample from to complete the image.
-
Image denoising: given an image corrupted by noise, model the posterior distribution and sample/use exact inference to predict the original image.
-
Language models:
-
generation: sample from a probability distribution over sequences of words or characters.
-
machine translation:
-
-
Audio models:
-
upsampling or super-resolution: increase resolution of an audio signal by calculating signal values at intermediate points. Sampling/perform inference on
-
speech synthesis
-
speech recognition
-
Sidenotes
- Judea Pearl was awarded the 2011 Turing award (Nobel prize of computer science) for founding the field of probabilistic graphical modeling.
- For a philosophical discussion of why one should use probability theory as opposed to something else: see the Dutch book argument for probabilism.
Representation: Bayesian networks
Bayesian networks are directed graphical models in which each factor depends only on a small number of ancestor variables:
where is a subset of .
When the variables are discrete, we may think of the possible values of as probability tables. If each variable takes d values and has at most ancestors, the entire table will contain at most . With one table per variable, the entire probability distribution can be compactly described with only parameters compared to with a naive approach.
Edges indicate dependency relationships between a node and its ancestors .
Formal definition
A Bayesian network is a directed graph together with:
- a random variable for each node
- one conditional probability distribution per node
A probability factorizes over a DAG (directed acyclic graph) if it can be decomposed into a product of factors, as specified by .
We can show by counter-example that when contains cycles, its associated probability may not sum to one.
Dependencies
Let be the set of all independencies that hold for a joint distribution . E.g., if , then
Independencies can be recovered from the graph by looking at three types of structures:
-
Common parent:
-
if is of the form , and is observed, then ( given ).
-
However, if is unobserved then .
-
Intuitively, contains all the information that determines the outcome of and ; once it is observed, nothing else affects their outcome (it does not matter what value or take respective to the outcome of and , respectively).
-
-
Cascade:
-
if equals and is observed, then .
-
However, if is unobserved, then .
-
-
V-structure:
-
if is , then knowing couples and . I.e. if is unobserved, but ( is observed).
-
E.g. suppose is true if the lawn is wet and false otherwise. (it rained) and (the sprinkler turned on) are two explanations for it being wet. If we know that is true (grass is wet) and is false (the sprinkler didn't go on), then (only other possible explanation). Hence, and are not independent given .
We can extend these structures by applying them recursively to any larger Bayesian net. This leads to a notion called d-separation (where d stands for directed).
Let , and be three sets of nodes in a Bayesian Network . We say that and are d-separated given (i.e. the nodes in are observed) if and are not connected by an active path. An undirected path in is called active given observed variables if for every consecutive triple of variables on the path, one of the following holds:
-
and is unobserved
-
and is unobserved
-
and is unobserved
-
and or any of its descendants are observed.
(i.e. there is pairwise dependency between consecutive variables on the path)
-
In the following example, and are d-separated given (you cannot infer from given ):
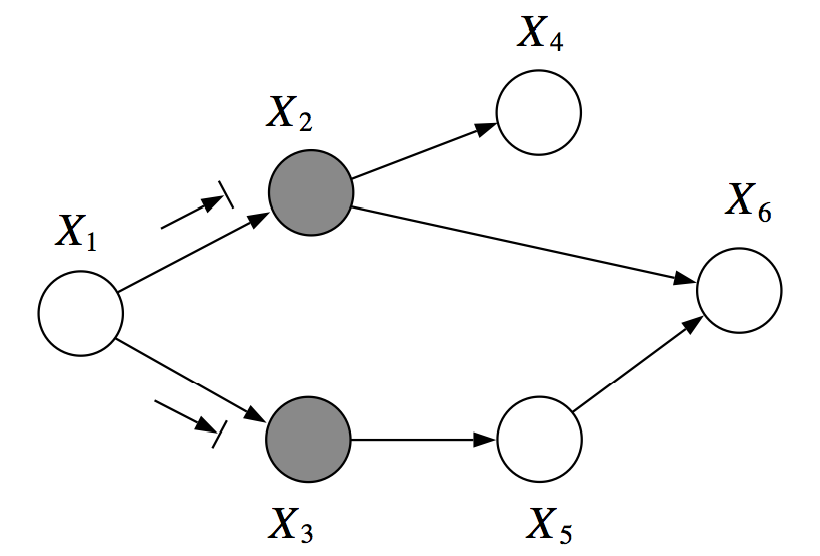
However, in the next example, are not d-separated given . There is an active path which passed through the V-structure created when is observed:
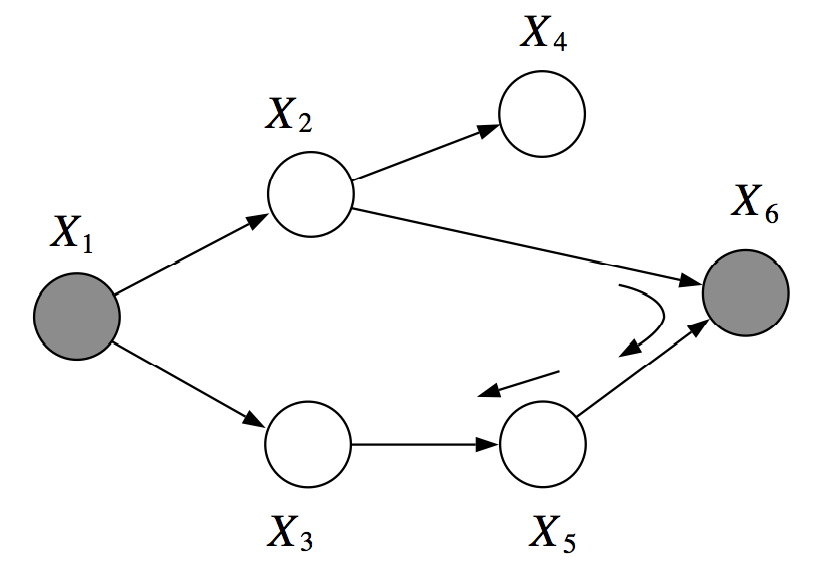
Let be a set of variables that are d-separated in .
I-map: If factorizes over , then . We say that is an I-map (independence map) for .
The intuition is that if and are mutually dependent, so are . Thus, we can look at adjacent nodes and propagate dependencies.
In other words, all the independencies encoded in are sound: variables that are d-separated in are truly independent in . However, the converse is not true: a distribution may factorize over , yet have independencies that are not captured in .
Note that if then this distribution still factorizes over the graph since we can always write it as where does not actually vary with . However, we can construct a graph that matches the structure of by simply removing that unnecessary edge.
Representational power of directed graphs
Can directed graphs express all the independencies of any distribution ? More formally, given a distribution , can we construct a graph such that ?
First, note that it is easy to construct a such that ; A fully connected DAG is an I-map for any distribution since (there are no variables which are d-separated in since one can always find an active path; the trivial one is the one that connects the two variables and thus creates the dependency).
A more interesting question is whether we can find a minimal I-map. We may start with a fully connected and remove edges until is no longer an I-map (i.e. encodes independences that are not in therefore no longer factorizes to ). One pruning method consist in following the natural topological ordering of the graph and removing node ancestors until this is no longer possible (see structure learning at the end of course).
Does any probability distribution always admit a perfect map for which . Unfortunately, the answer is no.\
For example, consider the following distribution over three variables (noisy-xor example)):
- we sample from a Bernoulli distribution, and we set ( only when one of or equals one).
- but (we can deduct from the other two). Thus, is an I-map for (every independency we can observe from is encoded in ), but and are not in (since the edge automatically creates an active path). The only way to capture all three independencies is to have all three nodes separated but this would not be an I-map (since would also be included). None of the 3-node graph structures that we discussed perfectly describes , and hence this distribution doesn't have a perfect map.
A related question is whether perfect maps are unique when they exist. Again, this is not the case, as and encode the same independencies, yet form different graphs. Two bayes nets are I-equivalent if they encode the same dependencies .
When are two Bayesian nets I-equivalent?
Each of the graphs below have the same skeleton (if we drop the directionality of the arrows, we obtain the same undirected graph)
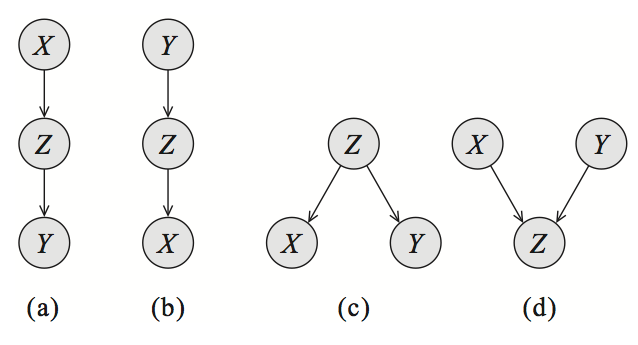
a,b and c are symmetric ( but ). They encode exactly the same dependencies and the directionality does not matter as long as we don't turn them into a V-structure (d). The V-structure is the only one that describes the dependency .
General result on I-equivalence: If have the same skeleton and the same V-structures, then .
Intuitively, two graphs are I-equivalent if the d-separation between variables is the same. We can flip the directionality of any edge, unless it forms a v-structure, and the d-connectivity of the graph will be unchanged. See the textbook of Koller and Friedman for a full proof in Theorem 3.7 (page 77).
Representation: Markov random fields
In Bayesian networks, unless we want to introduce false independencies among the variables, we must fall back to a less compact representation (with additional, unnecessary edges). This leads to extra parameters in the model and makes it more difficult for the model to learn them.
Markov Random Fields (MRFs) are based on undirected graphs. They can compactly represent independence assumptions that directed models cannot.
Unlike in the directed case, we are not saying anything about how one variable is generated from another set of variables (as a conditional probability distribution would). We simply indicated a level of coupling between dependent variables in the graph. This requires less prior knowledge, as we no longe have to specify a full generative story of how certain variables are constructed from others. We simply identify dependent variables and define the strength of their interactions. This defines an energy landscape over the space of possible assignments and we convert this energy to a probability via the normalization constant.
Formal definition
A Markov Random Field is a probability distribution over variables defined by an undirected graph .
- denotes the set of cliques. A clique is a fully connected subgraph, i.e. two distinct vertices in the clique are adjacent. It can be a single node, an edge, a triangle, etc.
- Each factor is a non-negative function over the variables in a clique.
- The partition function is a normalizing constant
Note: we do not need to specify a factor for each clique.
Example
we are modeling preferences among . are friends and friends have similar voting preferences.
where .
The final probability is:
where
Comparison to Bayesian networks
In the previous example, we had a distribution over that satisfied and (since only friends directly influence a person's vote). We can check by counter-example that these independencies cannot be perfectly represented by a Bayesian network. However, the MRF turns out to be a perfect map for this distribution.
Advantages:
- can be applied to a wider range of problems in which there is no natural directionality in variable dependencies
- can succinctly express certain dependencies that Bayesian nets cannot (converse is also true)
Drawbacks:
- computing the normalization constant requires summing over a potentially exponential number of assignments. NP-hard in the general case; thus many undirected models are intractable and require approximation techniques.
- difficult to interpret
- much easier to generate data from a Bayesian network.
Bayesian networks are a special case of MRFs with a very specific type of clique factor (one that corresponds to a conditional probability distribution and implies a directed acyclic structure in the graph), and a normalizing constant of one.
Moralization
A Bayesian network can always be converted into an undirected network with normalization constant one by adding side edges to all parents of a given node and removing their directionality.
The converse is also possible, but may be intractable and may produce a very large directed graph (e.g. fully connected).
A general rule of thumb is to use Bayesian networks whenever possible and only switch to MRFs if there is no natural way to model the problem with a directed graph (like the voting example).
Independencies in Markov Random Fields
Variables and are dependent if they are connected by a path of unobserved variables. However, if 's neighbors are all observed, then is independent of all the other variables (since they influence only via its neighbors, referred to as the Markov blanket of ).
If a set of observed variables forms a cut-set between two halves of the graph, then variables in one half are independent from ones in the other.
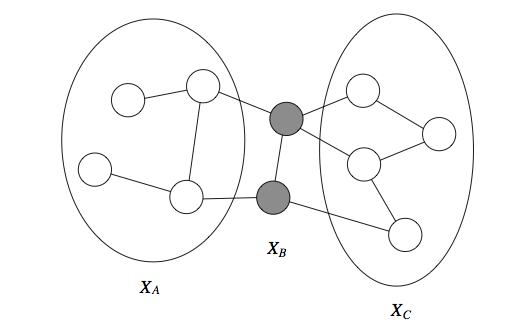
We define the Markov blanket of a variable as the minimal set of nodes such that is independent from the rest of the graph if is observed. This holds for both directed and undirected models. For undirected models, the Markov blanket is simply equal to a node's neighborhood.
Just as in the directed case, , but the converse is not necessarily true. E.g.:
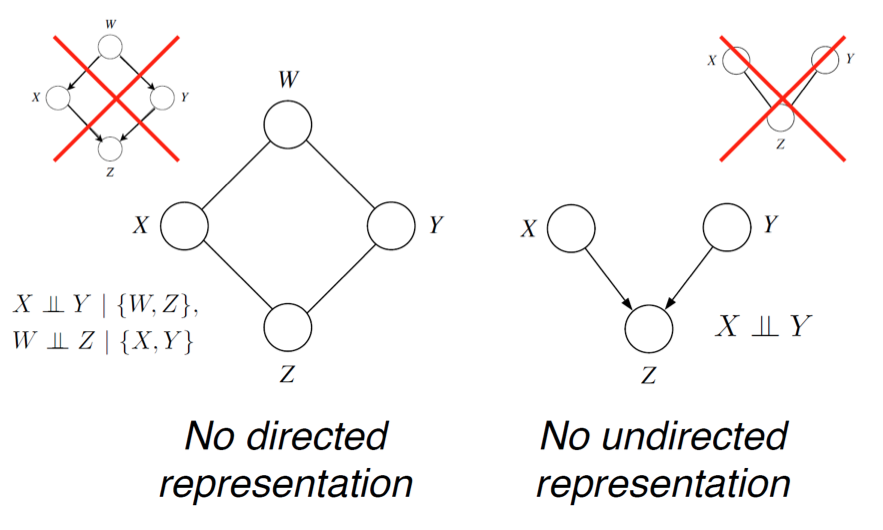
Conditional Random Fields
Special case of Markov Random Fields when they are applied to model a conditional probability distribution where are vector-valued variables. This common setting in supervised learning is also known as structured prediction.
Formal definition
A CRF is a Markov network over variables which specifies a conditional distribution:
with partition function:
The partition function depends on . encodes a different probability function for each . Therefore, a conditional random field results in an instantiation of a new Markov Random Field for each input .
Example
Recognize word from a sequence of black-and-white character images (pixel matrices of size ). The output is a sequence of alphabet letters
We could train a classifier to separately predict each from its . However, since the letters together form a word, the predictions across different positions ought to inform each other.
is a CRF with two types of factors:
- image factors for which assign higher values to that are consistent with an input . Can be seen as given by standard softmax regression e.g.
- pairwise factors for . Can be seen as empirical frequencies of letter co-occurences obtained from a large corpus of text.
We can jointly infer the structured label using MAP inference:
CRF features
In most practical applications, we assume that the factors are of the form:
where is an arbitrary set of features describing the compatibility between and .
In the above example:
- may be the probability of letter produced by logistic regression or a neural network evaluated on pixels .
- where are two letters of the alphabet. The CRF would then learn weights that would assign more weight to more common probability of consecutive letters (useful when given is ambiguous).
CRF features can be arbitrarily complex. We can define a model with factors that depend on the entire input . Does not affect computational performance since is observed (does not change the scope of the factors, just their values).
MRF models the joint distribution and needs to fit two distributions and . However, if we want to predict given , modeling is unnecessary and disadvantageous to do so:
- statistically: not enough data to fit both and because, since the models have shared parameters (the same graph), fitting one may not result in the best parameters for the other
- computationally: we also need to make simplifying assumption in the distribution so that can be tractable.
CRFs forgo this assumption and often perform better on prediction tasks.
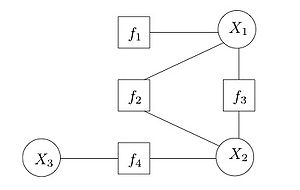
Factor Graphs
Bipartite graph where one group is the variables (round nodes) in the distribution being modeled and the other group is the factors defined on these variables (square nodes). Useful to see factor dependencies between variables explicitly, and facilitates computation.
Representation: Variable elimination (VE)
- Marginal inference: probability of a given variable
- Maximum a posteriori (MAP) inference: most likely assignment to the variables in the model possibly conditioned on evidence
NP-hard: whether inference is tractable depends on the structure of the graph. If problem is intractable, we use approximate inference methods.
Variable elimination is an exact inference algorithm. Let be discrete variables taking possible values each (also extends to continuous distributions).
Example
Chain Bayesian network:
How to compute marginal probability ?
Naive way is summing probability over all assignments:
we can do much better by leveraging factorization in probability distribution:
Each has complexity and we calculate of them, thus overall complexity is (much better than ).
Formal Definition
Graphical model as product of factors:
Variable elimination algorithm (instance of dynamic programming) performs two factor operations:
- product . denotes an assignment to the variables in the scope of e.g.:
- marginalization: . is the marginalized factor and does not necessarily correspond to a probability distribution even if was a CPD.
Marginalizing from . For : .
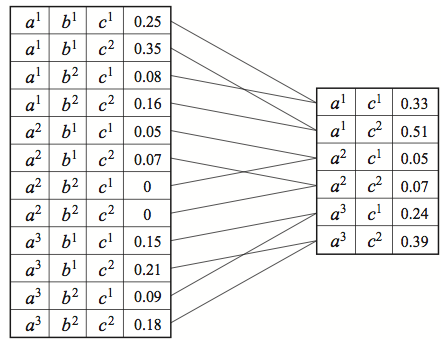
Variable elimination requires an ordering over the variables according to which variables will be eliminated (e.g. ordering implied by the DAG, see example).
- the ordering affects the running time (as the variables become more coupled)
- finding the best ordering is NP-hard
Let the ordering be fixed. According to , for each variable :
-
Multiply all factors containing
-
Marginalize out to obtain new factor
-
replace factors with
Running time of Variable Elimination is where is the maximum size (number of variables) of any factor formed during the elimination process and is the number of variables.
Choosing optimal VE ordering is NP-hard. In practice, we resort to heuristics:
- min-neighbors: choose variable with fewest dependent variables
- min-weight: choose variables to minimize the product of cardinalities of its dependent variables
- min-fill: choose vertices to minimize the size of the factor that will be added to the graph
Junction Tree (JT) algorithm
When computing marginals, VE produces many intermediate factors as a side-product. These factors are the same as the ones that we need to answer other marginal queries. By caching them, we can answer new marginal queries at no additional cost.
VE and JT algorithm are two flavors of dynamic programming: top-down DP vs bottom-up table filling.
JT first executes two runs of VE to initialize a particular data structure: bottom-up to get root probabilities ; and top-down to get leaf probabilities . It can then answer marginal queries in time.
Two variants: belief propagation (BP) (applies to tree-structured graphs) and full junction tree method (general networks).
Belief propagation
Variable elimination as message passing
Consider running VE algorithm on a tree to compute marginal . Optimal ordering: rooting the tree at and iterating in post-order (leaves to root s.t. nodes are visited after their children). This ordering is optimal because the largest clique formed during VE has size 2.
At each step, eliminate by computing (where is parent of ). can be thought of as a message sent from to that summarizes all the information from the subtree rooted at .
Say, after computing we want to compute ; we would run VE again with as root. However, we already computed the messages received by when was root (since there is only one path connecting two nodes in a tree).
Message passing algorithm
(assumes tree structure)
- a node sends a message to a neighbor whenever it has received messages from all nodes besides .
- There will always be a node with a message to send, unless all the messages have been sent out.
- Since each edge can receive one message in both directions, all messages will have been sent out after steps (to get all marginals, we need all incoming messages for every node: bottom-up and then top-down).
- Messages are defined as intermediate factors in the VE algorithm
Two variants: sum-product message passing (for marginal inference) and max-product message passing (for MAP inference)
Sum-product message passing
(i.e. sum over all possible values taken by )
After computing all messages, we may answer any marginal query over in constant time:
Sum-product message passing for factor trees
Recall that a factor graph is a bipartite graph with edges going between variables and factors.
Two types of messages:
- variable-to-factor messages
- factor-to-variable messages
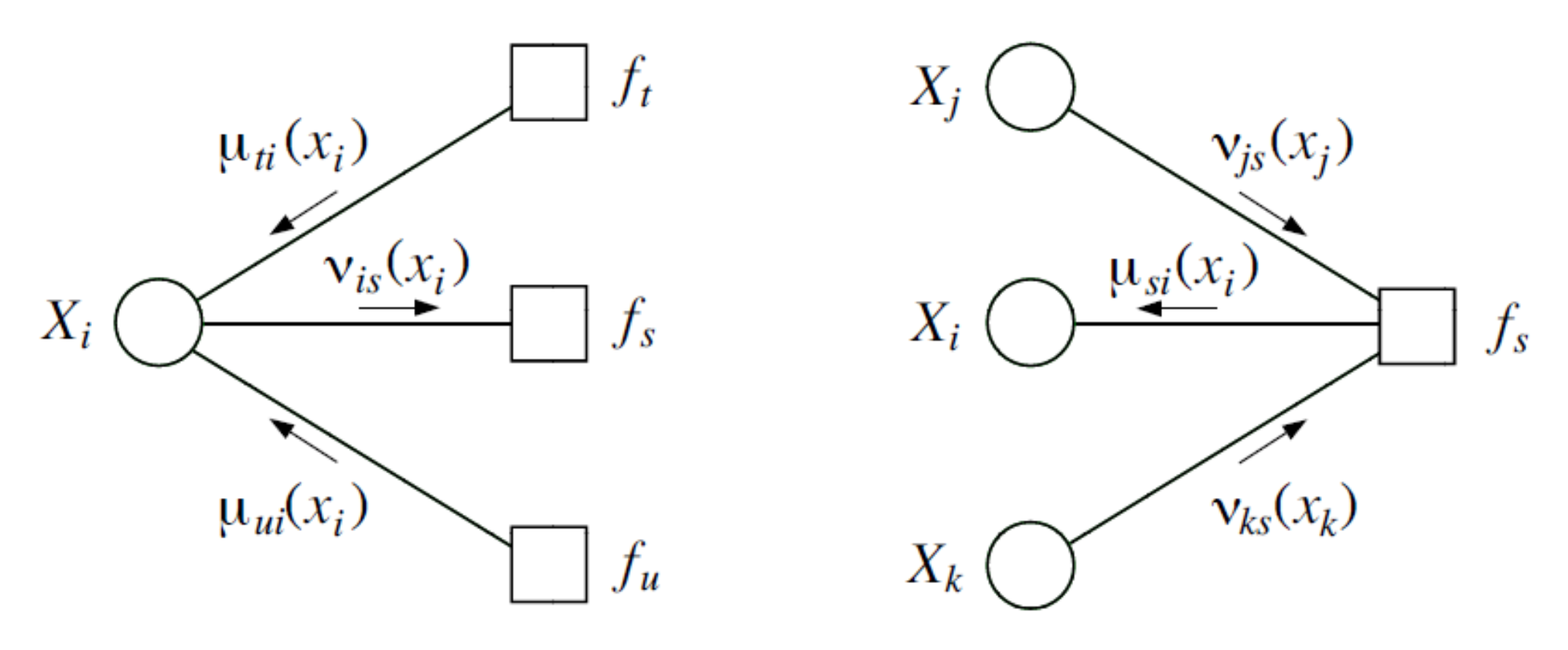
As long as there is a factor (or variable) ready to transmit to a variable (or factor), send message as defined above. Therefore, an edge receives exactly two messages (from variable to factor and factor to variable)
Max-product message passing
Since MRF factors are non-negative, max operator distributes over products, just like the sum (in general, max only distributes over products of non-negative factors, since within the max, two large negative factors can become a large positive factor, although taken separately, their maximum could be small positive factors).
E.g., for a chain MRF:
Since both problems decompose the same way we can reuse the same approach as for marginal inference (also applies to factor trees).
If we also want the , we can keep back-pointers during the optimization procedure.
Junction tree algorithm
- If graph not a tree, inference will not be tractable.
- However, we can partition the graph into a tree of clusters that are amenable to the variable elimination algorithm.
- Then we simply perform message-passing on this tree.
- Within a cluster, variables could be highly coupled but interactions among clusters will have a tree structure.
- yields tractable global solutions if the local problems can be solved exactly.
Suppose we have undirected graphical model (if directed, take the moralized graph). A junction tree over is a tree whose nodes are associated with subsets of the graph vertices (i.e. sets of variables). Must satisfy:
- family preservation: for each factor there is a cluster such that
- running intersection: for every pair of clusters , every cluster on the path between contains
Example of MRF with graph and junction tree :
- MRF potentials (i.e. product of the factors) are denoted using different colors
- circles are nodes of the junction tree
- rectangles are sepsets (separation sets) (= sets of variables shared by neighboring clusters)
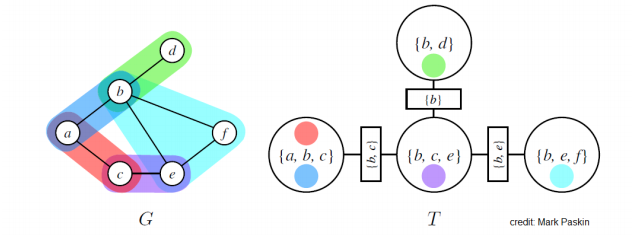
Trivial junction tree: one node containing all the variables in (useless because brute force marginalization algorithm)
Optimal trees make the clusters as small and modular as possible: NP hard to find one.
Special case: when itself is a tree, define a cluster for each edge.
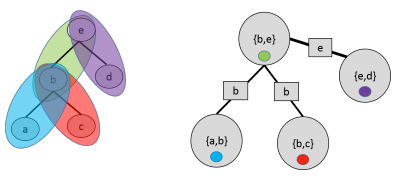
Example of invalid junction tree that does not satisfy running intersection property (green cluster should contain intersection of red and purple):
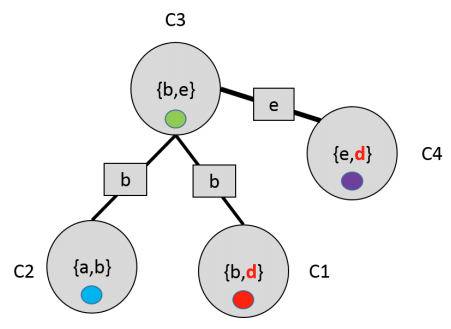
Algorithm
Let us define potential of each cluster as the product of all the factors in that have been assigned to .
By family preservation property, this is well defined and we may assume distribution in the form:
At each step of the algorithm, we choose a pair of adjacent clusters in and compute message whose scope is the sepset between the two clusters:
are variables in the cluster .
We choose only if has received messages from all of its neighbors except . Terminates in steps just as in belief propagation (bottom-up then top-down to get all messages).
We then define belief of each cluster based on all the messages that it receives:
(often referred to as Shafer-Shenoy updates)
Beliefs will be proportional to the marginal probabilities over their scopes: .
We answer queries of the form by marginalizing out the variable in its belief:
(requires brute force sum over all variables in )
Normalize by partition function (sum of all the beliefs in a cluster).
Running time is exponential in the size of the largest cluster (because we need to marginalize out variables from the cluster; must be done using brute force).
Variable elimination over a junction tree
Running VE with a certain ordering is equivalent to performing message passing on the junction tree.
We may prove correctness of the JT algorithm through an induction argument on the number of factors . The key property that makes this argument possible is the running intersection property (assures that it's safe to eliminate a variable from a leaf cluster that is not found in that cluster's sepset since it cannot occur anywhere except that one cluster)
The caching approach used for belief propagation extends to junction trees.
Finding a good junction tree
- by hand: model has regular structure for which there is an obvious solution (e.g. when model is a grid, clusters are pairs of adjacent rows)
- using variable elimination: running the VE elimination algorithm implicitly generates a junction tree over the variables. Thus, it is possible to use the heuristics discussed earlier
Loopy belief propagation
Technique for performing inference on complex (non-tree) graphs.
Running time of JT is exponential in size of the largest cluster. In some cases, we can give quick approximate solution.
Suppose we are given a MRF with pairwise potentials. Main idea is to disregard loops and perform message passing anyway.
Keep performing these updates for fixed number of steps or until convergence of messages. All messages are typically initialized with uniform distribution.
- Performs surprisingly well in practice
- Provably converges on trees and on graphs with at most one cycle
- However it may not converge and beliefs may not necessarily be equal to true marginals
- special case of variational inference algorithm
MAP Inference
- Intractable partition constant doesn't depend on and can be ignored.
- Marginal inference is summing all assignments, one of which is MAP assignment
- we could replace summation with maximization, however there exists more efficient methods
Many intractable problems as special case.\
E.g.: 3-sat. For each clause a factor if and otherwise. 3-sat instance satisfiable iff the value of the MAP assignment equals the number of clauses.
We may use similar construction to prove that marginal inference is NP-hard: add additional variable when all clauses are satisfied and otherwise. Its marginal probability will be iff the 3-sat instance is satisfiable
Example: image segmentation (input ; predict label indicating wether each pixel encodes the object we want to recover). Intuitively, neighboring pixels should have similar values. This prior knowledge can be modeled via an Ising model (see box 4.C p. 128 in Koller and Friedman)
Graph cuts
See Koller and Friedman 13.6
Efficient MAP inference algorithm for certain Potts models over binary-valued variables. Returns optimal solution in polynomial time regardless of structural complexity of the underlying graph.
A graph cut of undirected graph is a partition of nodes into 2 disjoint sets , . Let each edge be associated with a non-negative cost. Cost of a graph cut is the sum of the costs of the edges that cross between the two partitions:
min-cut problem is finding the partition that minimizes the cost of the graph cut. See algorithms textbooks for details.
Reduction of MAP inference on a particular class of MRFs to the min-cut problem
See Metric MRFs model box 4.D p. 127 in Koller and Friedman
MRF over binary variables with pairwise factors in which edge energies (i.e., negative log-edge factors) take the form:
Each node has unary potential described by energy function (normalized by substracting the so that its with either or ).
Motivation comes from image segmentation: reduce discordance between adjacent variables.
Formulate as a min-cut problem in augmented graph: add special source and sink nodes
- represents the object (assignment of ) and the background (assignment of )
- remember that either or since we normalized
- node is connected to nodes with by an edge with weight
- node is connected to nodes with by edge with weight
- thus every node is either connected to the source or the sink
- an edge only makes a contribution to the cost of the cut if the nodes are on opposite sides and its contribution is the of the edge.
The cost of the cut (unary potentials and edge contributions) is precisely the energy of the assignment.
Segmentation task in a 2x2 MRF as a graph cut problem:
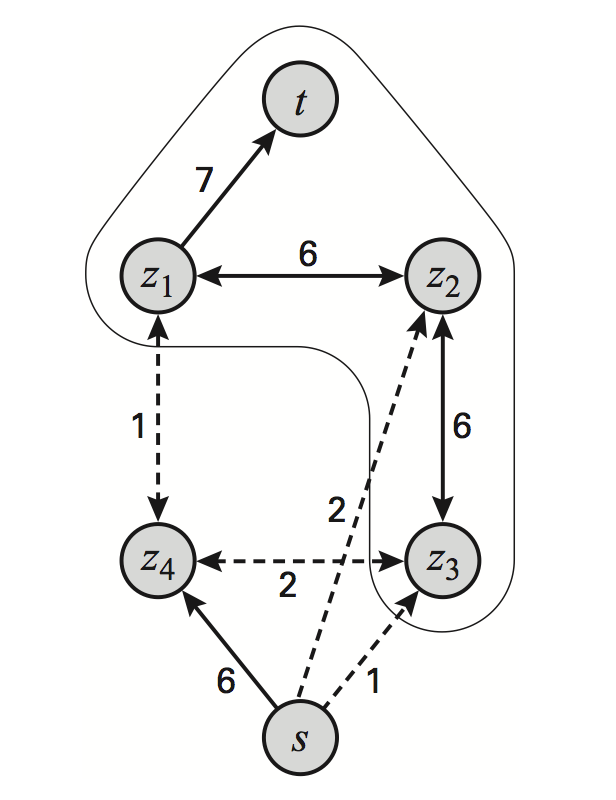
Refer to Koller and Friedman textbook for more general models with submodular edge potentials.
Linear programming approach
Graph-cut only applicable in restricted classes of MRFs.
Linear Programming (LP)
Linear programming (a.k.a. linear optimization) refers to problems of the form:
with , and .
- Has been extensively studied since the 1930s
- Major breakthrough of applied mathematics in the 1980s was the development of polynomial-time algorithms for linear programming
- Practical tools like CPLEX that can solve very large LP instances (100,000 variables or more) in reasonable time.
####Integer Linear Programming (ILP)
-
extension of linear programming which also requires
-
NP-hard in general
-
Nonetheless, many heuristics exist such as rounding:
-
relaxed constraint then round solution
-
works surprisingly well in practice and has theoretical guarantees for some classes of ILPs
-
Formulating MAP inference as ILP
Introduce two types of indicator variables:
- for each and state
- for each edge and pair of states
MAP objective becomes:
(function represents )
With constraints:
Assignments must also be consistent:
(we have to optimize over the edges too because an edge between two variables at given states contributes to the cost)
- solution to this linear program equals MAP assignment
- NP-hard but can transform this into an LP via relaxation
- in general, this method gives only approximate solutions
- for tree-structured graphs, relaxation is guaranteed to return integer solutions, which are optimal (see Koller and Friedman textbook for proof)
Dual decomposition
- See Sontag et al.
- See notes on Berkeley EE227C
Suppose MRF of the form:
Where denote arbitrary factors (e.g. edge potentials in pairwise MRF)
Consider decoupled objective:
Should encourage consistency between potentials:
(i.e. variable assignments chosen for an edge should be the same as for the corresponding nodes)
Lagrangian of the constrained problem ( and are assignments of the variable):
(lower bound with respect to is optimal value of the objective)
We can reparameterize the Lagrangian as:
Suppose we can find dual variables such that the local maximizers of and agree; in other words, we can find a such that and . Then we have that:
Second equalities follows because terms involving Lagrange multipliers cancel out when and agree.
On the other hand, by definition of :
which implies that .
Thus:
- bound given by Lagrangian can be made tight for the right choice of
- we can compute by finding a at which the local sub-problems agree with each other
Minimizing the objective
is continuous and convex (point-wise max of a set of affine functions, see EE227C), we may minimizing using subgradient descent or block coordinate descent (faster). Objective is not strongly convex, thus minimum is not global.
Recovering MAP assignment
As shown above, if a solution agrees for some , it is optimal.
If each has a unique maximum, problem is decodable. If some variables do not have a unique maximum, then we assign their optimal values to the ones that can be uniquely decoded to their optimal values and use exact inference to find the remaining variables' values. (NP-hard but usually not a big problem)
How can we decouple variables from each other? Isn't that impossible due to the edges costs?
Local search
Start with arbitrary assignment and perform "moves" on the joint assignment that locally increases the probability. No guarantees but prior knowledge makes effective moves.
Branch and bound
Exhaustive search over the space of assignments, while pruning branches that can be provably shown not to contain a MAP assignment (like backtracking ?). LP relaxation or its dual can be used to obtain upper bounds and prune trees.
Simulated annealing
Read more about this
Sampling methods (e.g. Metropolis-Hastings) to sample form:
is called the temperature:
- As , is close to the uniform distribution, which is easy to sample from
- As , places more weight on (quantity we want to recover). However, since the distribution is highly peaked, it is difficult to sample from.
Idea of simulated annealing is to run sampling algorithm starting with high and gradually decrease it. If "cooling rate" is sufficiently slow (requires lots of tuning), we are guaranteed to find the mode of the distribution.
Sampling methods
Interesting classes of models may not admit exact polynomial-time solutions at all.
Two families of approximate algorithms:
- variational methods (take their name from calculus of variations = optimizing functions that take other functions as arguments): formulate inference as an optimization problem
- sampling methods: main way of performing approximate inference over the past 15 years before variational methods emerged as viable and superior alternatives
Forward (aka ancestral) sampling
Bayesian network with multinomial variables. Samples variables in topological order:
- start by sampling variables with no parents
- then sample from the next generation by conditioning on the values sampled before
- proceed until all variables have been sampled
linear time by taking exactly 1 multinomial sample from each CPD
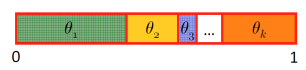
Assume multinomial distribution with outcomes and associated probabilties . Subdivide unit interval into regions with size and sample uniformly from :
Forward sampling can also be performed on undirected models if the model can be represented by a clique tree with a small number of variables per node:
- calibrate clique tree; gives us marginal distribution over each node and choose node to be root
- marginalize over variables in the root node to get the marginal for a single variable
- sample from each variables in the node, each time incorporating newly sampled values as evidence
- move down the tree to sample from other nodes and send updated message containing values of the sampled variables.
Monte Carlo estimation
Name refers to famous casino in Monaco. Term was coined as codeword by physicists working on the atomic bomb as part of the Manhattan project.
Constructs solutions based on large number of samples. E.g. consider the following integral:
Since samples are i.i.d., MC estimate is unbiased and variance is inversely proportional to .
Rejection sampling
Special case of Monte Carlo integration. Compute area of a region by sampling in a larger region with known area and recording the fraction of samples that falls within .
E.g., Bayesian network over set of variables . We use rejection sampling to compute marginal probabilities :
and then take the Monte Carlo approximation.
Importance sampling
See Art Owen's lecture notes about importance sampling
Suppose we want to compute where is nearly zero outside a region for which is small. A plain Monte Carlo sample would be very wasteful and could fail to have even one point inside the region .
Let be a known probability density function (importance sampling distribution):
The importance sampling estimate of is:
Assuming we can compute
We have (unbiased estimate) and:
where
Therefore, the numerator is small when is nearly proportional to . Small values of greatly magnify whatever lack of proportionality appears in the numerator. It is good for q to have spikes in the same places that does.
Having follow a uniform distribution collapses to plain Monte Carlo.
Normalized importance sampling
When estimating fraction of two probabilities (e.g. a conditional proba), if we sample each proba separately, errors compound and variance can be high. If we use the same samples to evaluate the fraction, estimator is biased but asymptotically unbiased and we avoid the issue of compounding errors.
See notes on website
Markov Chain Monte Carlo
Developped during the Manhattan project. One of the 10 most important algorithms of the 20th century.
Used to perform marginal and MAP inference as opposed to computing expectations.
We construct a Markov chain whose states are joint assignments of the variables and whose stationary distribution equals the model probability .
-
Run Markov chain from initial state for burn-in steps (number of steps needed to converge to stationary distribution, see mixing time)
-
Run Markov chain for sampling steps
We produce Monte Carlo estimates of marginal probabilities. We then take the sample with highest probability to perform MAP inference.
Two algorithms:
- Metropolis-Hastings
- Gibbs sampling (special case of Metropolis-Hastings)
For distributions that have narrow modes, the algorithm will sample from a given mode for a long time with high probability. Therefore, convergence will be slow.
See Markov Chain Monte Carlo without detailed balance
Variational Inference
Inference as an optimization problem: given intractable distribution and class of tractable distributions , find that is most similar to .
Unlike sampling-based methods:
- variational approaches will not find globally optimal solution
- but we always know if they have converged and even have bounds on their accuracy
- scale better and more amenable to techniques like stochastic gradient optimization, parallelization over multiple processors, acceleration using GPUs
Kullback-Leibler divergence
Need to choose approximation family and optimization objective that captures similarity between and . Information theory provides us with Kullback-Leibler (KL) divergence.
For two distributions with discrete support:
with properties:
iff
It is however asymmetric: . That is why it is called a divergence and not a distance.
Variational lower bound
Use unnormalized distribution instead of because evaluating is intractable because of normalization constant.
Important property:
Therefore
is called the variational lower bound or evidence lower bound (ELBO) and often written in the form:
E.g.: If we are trying to compute marginal probability , minimizing amounts to maximizing a lower bound on log-likelihood of the observed data.
By maximizing evidence-lower bound, we are minimizing by squeezing it between and .
or ?
Computationally, computing involves an expectation with respect to which is typically intractable to evaluate
is called the I-projection (information projection) and is infinite when and . Therefore, if we must have . We say that is zero-forcing for and it under-estimates the support of . It is called the inclusive KL divergence.
is called the M-projection (moment projection) and is infinite if and thus if we must have . is zero-avoiding for and it over-estimates the support of . It is called the exclusive KL divergence.
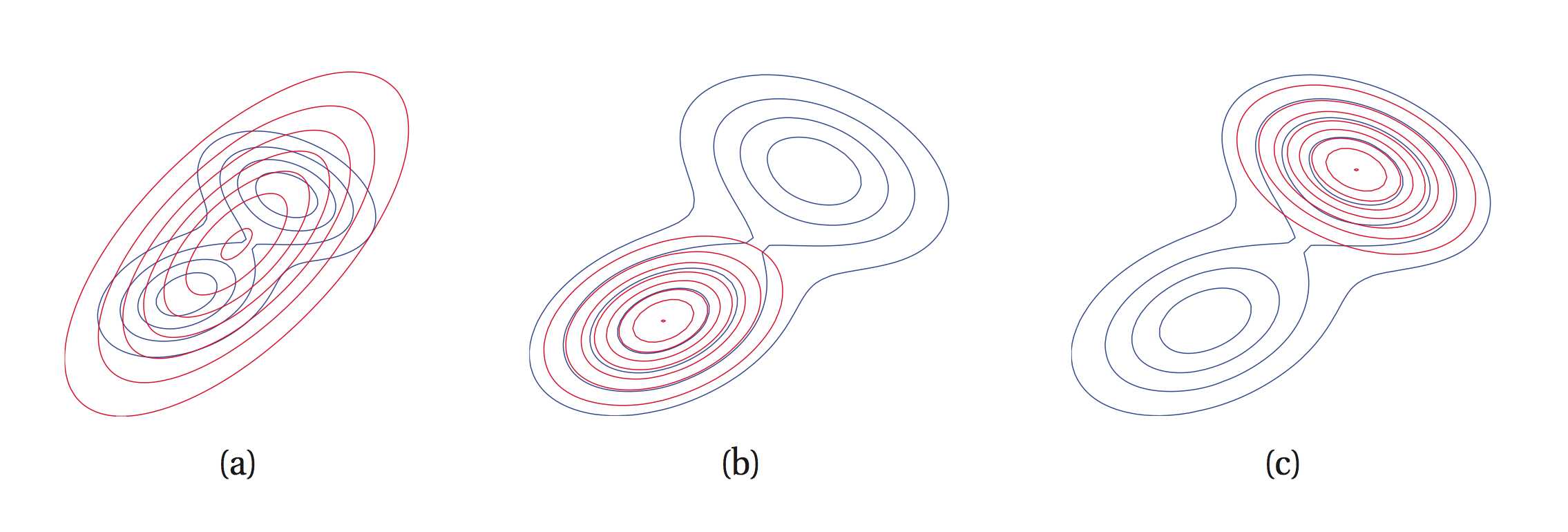
E.g.: fitting unimodal approximating distribution (red) to multimodal (blue). leads to a) and leads to b) and c).
Mean-field inference
How to choose approximating family ?
One of most widely used classes is set of fully-factored . Each is a categorical distribution over a one-dimensional discrete variable. This is called mean-field inference and consists in solving:
via coordinate descent over the .
For one coordinate, the optimization has a closed form solution:
To compute we only need the factors belonging to the Markov blanket of . If variables are discrete with possible values and there are factors and variables in the Markov blanket of then computing expectation takes time (for each value of we sum over all assignments of the variables and, in each case, sum over the factors.)
Learning in directed models
Two different learning tasks:
- parameter learning, graph structure is known and we want to estimate the factors
- structure learning, estimate the graph
Possible use cases:
- density estimation: want full distribution so that we can compute conditional probabilities
- specific prediction task
- structure or knowledge discovery (interested in the model itself)
Maximum likelihood
Want to construct as close as possible to in order to perform density estimation. Use KL divergence:
Hence minimizing KL divergence is equivalent to maximizing expected log-likelihood ( must assign high probability to instances sampled from )
Since we do not know , we use a Monte-Carlo estimate of the expected log-likelihood and maximum likelihood learning is defined as:
Likelihood, Loss and Risk
Minimize expected loss or risk:
Loss that corresponds to maximum likelihood is the log loss:
For CRFs we use conditional log likelihood
For prediction, we can use classification error (probability of predicting the wrong assignment).
Better choice might be hamming loss (fraction of variables whose MAP assigment differs from ground truth).
Work on generalizing hinge loss (from SVM) to CRFs which leads to structured support vector machines.
Maximum likelihood learning in Bayesian networks
Given Bayesian network and i.i.d. samples ( parameters are the conditional probabilities)
Likelihood is
Taking log and combinining same values:
Thus:
Maximum-likelihood estimate has closed-form solution: simplicity of learning is one of the most convenient features of Bayesian networks.
Learning in undirected models
- higher expressivity, thus more difficult to deal with
- maximum likelihood learning can be reduced to repeatedly performing inference
Learning Markov Random Fields
where is a vector of indicator functions and is the set of all model parameters defined by
Partition function equals to one for Bayesian networks but MRFs do not make this assumption.
Exponential families
See Stanford CS229 course
- exponential families are log-concave in their natural parameters
- is called vector of sufficient statistics. E.g. if is Gaussian, contains mean and variance
- exponential families make the fewest unnecessary assumptions about the data disribution. Formally, distribution maximizing entropy under constraint is in the exponential family.
- admit conjugate priors which makes them applicable in variational inference
Maximum likelihood learning of MRFs
Since we are working with an exponential family, maximum likelihood will be concave.
The log-likelihood is:
First term is decomposable in , second is not and it's hard to evaluate.
Computing the gradient of requires inference with respect to which is intractable in general:
Moreover, the Hessian is:
Covariance matrices are always positive semi-definite, which is why is convex.
Usually non-convexity is what makes optimization intractable but in this case it is the computation of the gradient.
Approximate learning techniques
Maximum-likelihood learning reduces to repeatedly using inference to compute the gradient and then change model weights using gradient descent.
- Gibbs sampling from distribution at each step of gradient descent; then approximate gradient using Monte-Carlo
- persistent contrastive divergence (used to train Restricted Boltzmann Machines; see link) which re-uses same Markov Chain between iterations (since model has changed very little)
Pseudo-likelihood
For each example , pseudo likelihood makes the approximation: where is the -th variable in and is the Markov blanket of (i.e. neighbors). Since each term involves one variable, we only need to sum over the values of one variable to get its partition function (tractable).
Pseudo-likelihood objective assumes that depends mainly on its neighbors in the graph.
Pseudo-likelihood converges towards true likelihood as number of data points increases.
Moment matching
Recall, log-likelihood of MRF:
Taking the gradient (see intro of chapter for details):
This is precisely the difference between expectations of natural parameters under empirical (data) and model distribution.
is a vector of indicator functions for the variables of a clique: one entry equals for some .
The log-likelihood objective forces model marginals to match empirical marginals. This property is called moment matching.
When minimizing inclusive KL-divergence , minimizer will match the moments of the sufficient statistics to the corresponding moments of .
MLE estimate is minimizer of where is the empirical distribution of the data. In variational inference, minimization over in smaller set of distributions is known as M-projection ("moment projection").
Learning in conditional random fields
where:
We can reparameterize it as we did for MRFs:
Log-likelihood given dataset is:
There is a different partition function for each data point since it is dependent on .
The gradient is now
And the Hessian is the covariance matrix
Conditional log-likelihood is still concave, but computing the gradient now requires one inference per training data point, therefore gradient ascent is more expensive than for MRFs.
One should try to limit the number of variables or make sure that the model's graph is not too densely connected.
Popular objective for training CRFs: max-margin loss, a generalization of the objective for training SVMs. Models trained using this loss are called structured support vector machines or max-margin networks. This loss is more widely used in practice. Only requires MAP inference rather than general (e.g. marginal inference).
Learning in latent variables models (LVMs)
- LVMs enable us to leverage prior knowledge. E.g. language model of news articles. We know our set of news articles is a mixture of distinct distributions (one for each topic). Let be an article and a topic (unobserved variable), we may build a more accurate model . We now learn a separate for each topic rather than trying to model everything with one . However, since is unobserved we cannot use the previous learning methods.
- LVMs also increase the expressive power of the model.
Formally, latent variable model is probability distribution over two sets of variables :
where is observed and is unobserved.
Example: Gaussian Mixture Models\
see CS289 lecture notes on GMMs
Marginal likelihood training
Maximize marginal log-likelihood of the data:
Whereas a single exponential family distribution has concave log-likelihood, the log of a weighted mixture of such distributions is no longer concave or convex.
Learning latent variable models
Expectation-Mazimization algorithm
- See CS289 lecture notes EM-algorithm
- The class website notes use the fact that an exponential family is entirely described by its sufficient statistics to derive the optimal assignment of and in the GMM example.
EM as variational inference
Why does EM converge?
Consider posterior inference problem for . We apply our variational inference framework by taking to be the unnormalized distribution; in that case, will be the normalization constant (maximizing it maximizes the likelihood).
Recall that variational inference maximizes the evidence lower bound (ELBO):
over distributions . The ELBO satisfies the equation
Hence, is maximized when ; in that case the KL term becomes zero and the lower bound is tight:
The EM algorithm can be seen as iteratively optimizing the ELBO over (at the E step) and over (at the M) step.
Starting at some , we compute the posterior at the step. We evaluate the ELBO for ; this makes the ELBO tight:
Next, we optimize the ELBO over , holding fixed. We solve the problem
This is precisely the optimization problem solved at the step of EM (in the above equation, there is an additive constant independent of ).
Solving this problem increases the ELBO. However, since we fixed to , the ELBO evaluated at the new is no longer tight. But since the ELBO was equal to before optimization, we know that the true log-likelihood must have increased.
- Every step increases the marginal likelihood , which is what we wanted to show.
- Since the marginal likelihood is upper-bounded by its true global maximum, EM must eventually converge (however objective is non-convex so we have no guarantee to find the global optimum; heavily dependent on initial )
Bayesian learning
Example of limits of maximum likelihood estimation:
- we're not taking into account the confidence in our estimate considering the sample size
- no prior distribution of the parameters: e.g. for out of vocabulary words, their probability will be zero.
In Bayesian learning both observed variables and parameters are random variables. We're taking uncertainty over the parameters into account.
Prior distribution encodes our initial beliefs. Choice of prior is subjective.
Useful when we want to provide uncertainty estimates about model parameters or when we encounter out of sample data.
Conjugate priors
For some choices of priors , the posterior can be computed in close form.
Suppose:
Then:
No need to compute: where the integral is intractable.
Beta distribution
where is a normalization constant.
If , we believe heads are more likely:
As or increase, variance decreases, i.e. we are more certain about the value of :
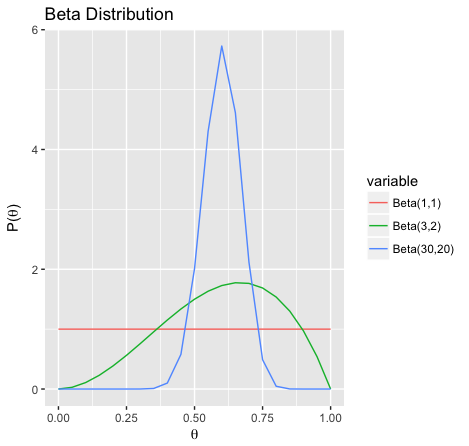
The Beta distribution family is a conjugate prior to the Bernoulli distribution family, i.e. if is a Beta distribution and is a Bernoulli distribution then is still a Beta distribution.
Categorical Distribution
Parameter of the categorical distribution:
where sums to 1.
The Dirichlet distribution is the conjugate prior for the categorical distribution. Dirichlet distribution is defined by parameter and its pdf is:
Used in topic modeling (e.g. latent dirichlet allocation)
Limits of conjugate priors
- restricts the kind of priors we can use
- for more complex distributions, posterior can still be NP hard to compute
Practitioners should compare it with other tools such as MCMC or variational inference.
Structure learning for bayesian networks
Learn structure of Directed Acyclic Graph from data. Two approaches: score-based and constraint-based.
Score-based approach
Search over space of DAGs to maximize score metric.
Score metric: penalized log-likelihood
- : log-likelihood of the graph under graph structure
- parameters in are estimated based on MLE and log-likelihood score is calculated based on parameters
- if we only considered log-likelihood, we would end up with a complete graph (overfitting). Second term penalizes over-complicated structures.
- is the number of samples and is the number of parameters in
- For AIC: , for BIC: (for BIC, influence of model complexity decreases as the number of samples grow, allowing log-likelihood to dominate the score
Score metric: Bayesian Dirichlet score
When prior is Dirichlet distribution:
- : parent configuration of variable
- count of variable taking value with parent configuration
- counts in the prior
With prior for graph structure , BD score:
Overfitting is implicitly penalized via integral over parameter space.
Chow-Liu Algorithm
Finds maximum-likelihood tree where each node has at most one parent. We can simply use maximum likelihood as a score (already penalizing complexity by restricting ourselves to tree structures).
Likelihood decomposes into mutual information and entropy ().
Entropy is independent of tree structure (so we eliminate it from the maximization). Mutual information is symmetric, therefore edge orientation does not matter.
3 steps:
-
compute mutual information for all pairs of variables (edges):
where
complexity:
-
find maximum weight spanning tree (tree that connects all vertices) using Kruskal or Prim Algorithms (complexity: )
-
pick a node to be root variable, assign directions going outward of this node.
Search algorithms
-
local search: start with empty/complete graph. at each step, perform single operation on graph strucure (add/remove/reverse edge, while preserving acyclic property). If score increases, then adopt attempt otherwise, make other attempt.
-
greedy search (K3 algorithm): assume topological order of graph in advance (for every directed edge uv from vertex u to vertex v, u comes before v in the ordering). Restrict parent set to variables with a higher order. While searching for parent set for each variable, add parent that increases the score most until no improvement can be made. (Doesn't that create a complete graph? No: restricted by the topological order). When specified topological order is a poor one, results in bad graph structure (low graph score).
Space is highly non-convex and both algos might get stuck at sub-optimal regions.
Constraint-based approach
Employs independence test to identify a set of edge constraints for the graph and then finds best DAG that satisfies the constraint.
E.g.: distinguish V-structure and fork-structure by doing independence test for the two variables on the side conditional on the variable in the middle. Requires lots of data samples to guarantee testing power.
Recent advances
- order search (OS): search over topological orders and graph space at the same time. It swaps the order of two adjacent variables at each step and employs K3 algorithm as a sub-routine.
- ILP: encodes graph structure, scoring and acyclic constraint into ILP problem and uses solver. Approach requires a bound on the maximum number of parents of any node. Otherwise, number of constraints explodes and problem becomes intractable
Variational auto-encoder
Deep learning technique for learning latent representations.
Directed latent-variable model:
Deep generative model with layers:
Objectives:
- learning parameters of
- approximate posterior inference over (given image , what are its latent factors)
- approximate marginal inference over (given image with missing parts, how do we fill them in)
Assumptions:
- intractable posterior probability
- dataset is too large to fit in memory
Standard approaches?
- EM: need to compute posterior (intractable) + would need to use online version of EM to perform M-step.
- mean field: requires us to compute expectation. Time complexity scales exponentially with size of Markov blanket of target variable. For , if at least one component of depends on each component of , this introduces V-structure ( explains away differences among ) and Markov blanket of some contains all the other -variables (intractable)
- sampling-based methods: authors (Kingma and Welling) found that they don't scale well on large datasets
Auto-encoding variational Bayes
- seminal paper by Kingma and Welling
- variational auto-encoder is one instantation of this algo
ELBO:
satisfies equation:
We are conditioning on . Could we optimize over using mean field? No, assumption that is fully factored is too strong.
Approach: black-box variational inference
- gradient descent over (only assumption: differentiable as opposed to coordinate descent)
- simultaneously perform learning via gradient descent on both (keep ELBO tight around ) and (push up lower bound (hence )). Similar to EM algo.
We need to compute gradient:
For gradient over we can swap with expectation and estimate via Monte Carlo.
Gradient w.r.t. via the score function estimator (see Appendix B of Neural Variational Inference and Learning in Belief Networks):
(can evaluate using Monte-Carlo)
However, score function estimator has high variance. VAE paper proposes alternative estimator that is much better behaved.
SGVB estimator
$
= \mathbb{E}q \log p\theta (z) - KL(q_\phi (z\vert x) \Vert p(z))$
Thus the ELBO becomes:
Interpretation:
- calling the encoder, both terms take sample which we interpret as a code describing
- first term is log-likelihood of observed given code . is called decoder network and the term is called the reconstruction error
- second term is divergence between and prior , which is fixed to be a unit Normal. Encourages the codes to look Gaussian. It's a regularization term that prevents to encode a simple identity mapping.
- reminiscent of auto-encoder neural networks (learn by minimizing reconstruction loss ), hence the name.
Main contribution of the paper is a low-variance gradient estimator based on the reparameterization trick:
where noise variable is sampled from a simple distribution (e.g. standard normal) and deterministic transformation maps random noise into more complex distribution .
This approach has much lower variance (see appendix of this paper by Rezende et al.) than the score function estimator.
and are parameterized by neural networks (bridge between classical machine learning method (approximate Bayesian inference here) and modern deep learning):
where the and functions are neural nets (two dense hidden layers of 500 units each).
Experimental results:
- Monte-Carlo EM and hybrid Monte-Carlo are quite accurate, but don’t scale well to large datasets.
- Wake-sleep is a variational inference algorithm that scales much better; however it does not use the exact gradient of the ELBO (it uses an approximation), and hence it is not as accurate as AEVB.
See original paper
Papers that use VAE: