General propagation method is quite complex and can be simplified when the network is an AND-tree.
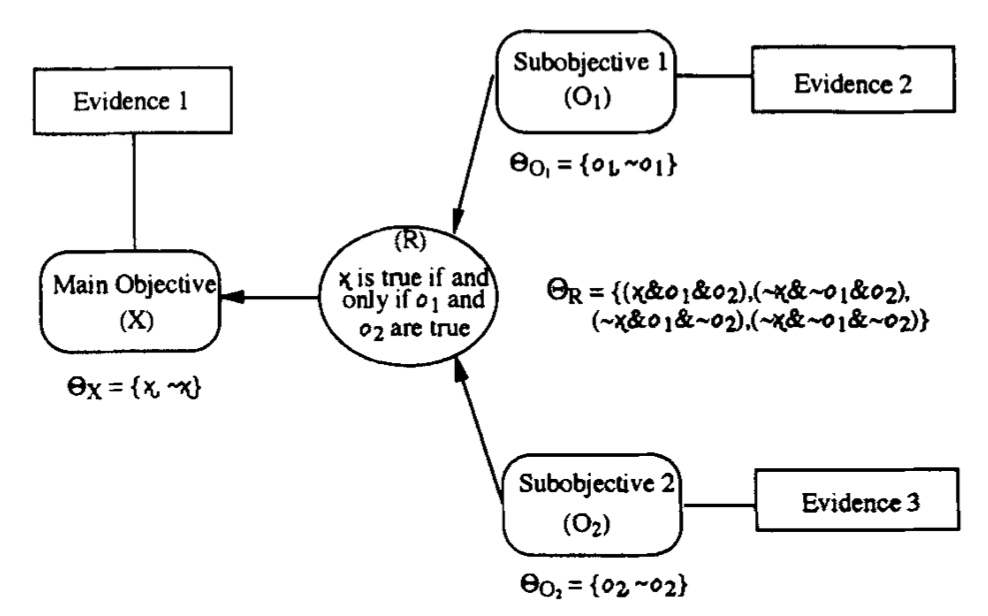
Consider simple evidential network with binary variables X, O1 and O2 with frames (values) ΘX={x,∼x}, ΘO1={o1,∼o1}, ΘO2={o2,∼o2}.
We assume O1,O2 are related to X through and AND node: X=x iff O1=o1 and O2=o2. This relationship is incorporated by assuming that the frame of the relational node R is:
Evidence for a variable is represented by a basic probability assignment (bpa) function:
mX=(m(x),m(∼x),m({x,∼x}))
We assumed one item of evidence for each variable. If more than one item of evidence bear on a node, we need to first combine the items of evidence using Dempster's rule of combination.
Recall from Dempster-Shafer theory
Vacuous Extension
Whenever a set of m-values is propagated from a smaller node (fewer variables) to a bigger node (more variables), the m-values are said to be vacuously extended onto the frame of the bigger node.
Suppose we have mO1(o1),mO1(∼o1),mO1({o1,∼o1}) defined on the frame ΘO1={o1,∼o1}
We want to vacuously extend them to a bigger node consisting of O1 and O2. Entire frame of combined node is given by cartesian product: ΘO1O2={(o1,o2),(∼o1,o2),(o1,∼o2),(∼o1,∼o2)}. The vacuous extension gives:
Propagating m-values from a node to a smaller node. Suppose we are marginalizing ΘO1O2 onto ΘO1. Similar to marginalization of probabilities, we sum all m-values over elements of the bigger frame that intersect with elements of the smaller frame:
evidence bearing directly on node X will impact indirectly O1 and O2
evidence at O1 or O2 will not affect X by themselves because of the AND
evidence at O1 alone will not affect O2 and vice-versa
These properties are special features of AND-trees: in general trees, each node is indirectly affected by the evidence at the other nodes (see Propagating belief functions with local computations, Shenoy and Shafer).
Let's denote:
mXT=⊕{mY∀ variable Y}↓X (combine all nodes and marginalize on X).
Goal is to compute mXT for all nodes X given mY for all nodes Y.
mX←{O1,…,On} denotes bpa function for X representing marginal of the combination of bpa functions mOi.
Proposition 1
Propagation of m-values from sub-objectives Oi to main objective X.
mX←all O’s(x)=∏i=1nmOi(oi)
mX←all O’s(∼x)=1−∏i=1nplausibility of oi[1−mOi(∼oi)]
Propagation of m-values to a given sub-objective Oi from the main objective X and other subobjectives Oj,j=i.
m_{O_i\leftarrow \text{X & all other O's}}(o_i) = K_i^{-1} m_X(x)\prod_{j\ne i}[1-m_{o_j}(\sim o_j)]
m_{O_i\leftarrow \text{X & all other O's}} (\sim o_i) = K_i^{-1} m_X(\sim x)\prod_{j\ne i}m_{O_j}(o_j)
m_{O_i\leftarrow \text{X & all other O's}}(\{o_i, \sim o_i\}) = 1-m_{O_i\leftarrow \text{X & all other O's}}(o_i) - m_{O_i\leftarrow \text{X & all other O's}}(\sim o_i)
where Ki is the normalization constant given by Ki=[1−mX(x)Ci] and Ci=1−∏j=i[1−moj(∼oj)] (measure of conflict).