1. Generative pre-training
Language modeling objective on unlabeled data using auto-regressive model:
where is the size of the context window and s the tokens in the corpus.
BooksCorpus dataset is used for training (7,000 unique unpublished books from a variety of genres). It contains long stretches of contiguous text, which allows the generative model to learn to condition on long-range information.
The 1B Word Benchmark used by ELMo is approximately the same size but is shuffled at a sentence level - destroying long-range structure.
2. Discriminative fine-tuning
Task-specific input adaptation and corresponding supervised objective
where . is the final transformer block's activation and is a task-specific parameter learned during fine-tuning.
Including language modeling as auxiliary objective to the fine-tuning improves generalization:
Pre-trained model is trained on contiguous sequences of text, thus inputs for fine-tuning tasks need to be adapted to a traversal-style approach:
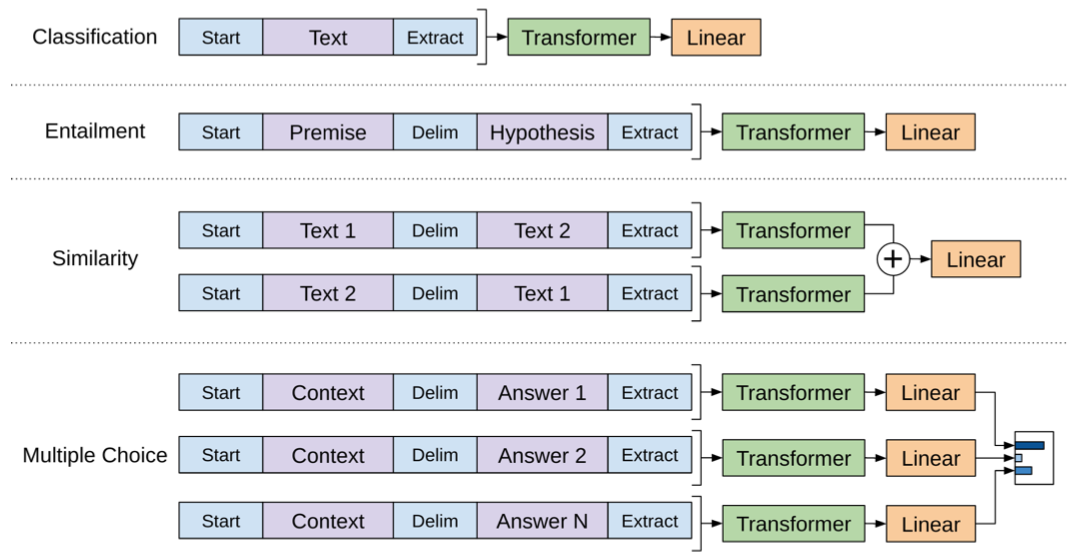
Embeddings for delimiter tokens are parameters that arise during fine-tuning.
Architecture
- multi-layer Transformer decoder
- provides structured memory for handling long-term dependencies than attention-augmented RNNs.
Results
(improvements are absolute)
- 86.5 / +8.9% on commonsense reasoning (Stories Cloze Test)
- 59 / +5.7% on question answering (RACE)
- 81.4 / +1.5% on textual entailment (MultiNLI) (judge relationship as entailment, contradiction or neutral)
- 72.8 / +5.5% on GLUE multi-task benchmark
Larger fine-tuning datasets benefit from the language model auxiliary objective but smaller datasets do not.
Transformers beats LSTM-based architectures on almost all datasets.
Notes
- Zero-shot behavior: perform task without supervised fine-tuning
- earliest approaches used unlabeled data to compute word-level or phrase-level statistics, then used as a feature in a supervised model before adopting to word embeddings
- used ftfy library to fix unicode that's broken and spaCy tokenizer
- Mathews correlation coefficient: measure of the quality of binary classification. Computed using confusion matrix, regarded as balanced measure which can be used even in the case of class imbalance (better than F1 score). See wikipedia.