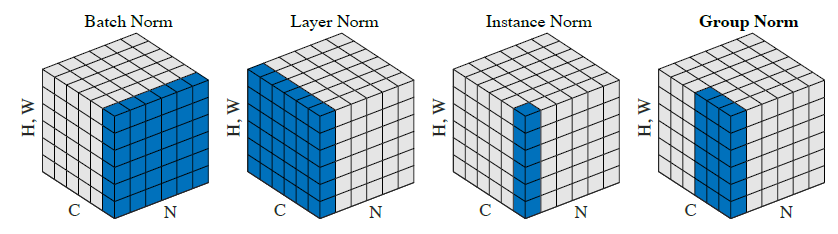
Batch normalization
Before the activation function, normalize each input dimension across the batch. If the input tensor where is the batch size:
where is the -th dimension of input vector and the mean and standard deviation are computed across the vector .
BatchNorm then applies some linear transformation (scale and shift): where and are learned during training.
The main criticism is that normalization is dependent on batch samples which can lead to different behavior during inference (since batch statistics change).
Batch norm is common for convoluted and fully connected networks.
LayerNorm
The key difference is that we normalize across the feature dimension (i.e. each sample in the batch is normalized individually): instead of , which removes the training vs inference discrepancy.
LayerNorm is common in transformers, LSTMs and GRUs. It works well for small batch sizes (that would result in noisy estimates for batch norm, leading to unstable training). During inference, batch size can be 1 in LLMs and during training, the models are so large that batch size is small.
RMSNorm
Lighter alternative to layer norm that skips mean computation: (bias is also omitted).
It is faster, utilizes less memory and achieves the same performance as LayerNorm. It was used in DeepSeekV3.
GroupNorm
This seems specific to convolutional networks. We normalize within groups of channels instead of across the batch or entire feature dimension.
Let's divide the channels (= features) across groups. For the first group, we normalize across:
where is the -th sample in the batch and is the group size.
When the number of groups is (), this is exactly layer norm.
When the number of groups is (, the number of channels), this is exactly instance norm.
The specificity to images here is that we are actually considering only one pixel but we actually normalize across all pixels together.
If (2D image flattened into 1D vector), we normalize across: .
The normalization parameter during the mean or standard deviation calculation is given by
For instance norm, normalization happens per channel, per sample removing the dependency on other samples. It is especially used in style transfer and GANs.