(MMoE by Google, 2018)
Multi-task learning: recommendation systems often need to optimize multiple objectives at the same time. E.g. click through rate, watch time and explicit feedback (rating).
However in practice, multi-task learning models underperform single-task models on their respective sub-tasks because they fail to model relationships among tasks (some can be conflicting). MMoE explicitly models task relationships and learns task-specific functionalities to leverage shared representations by allocating parameters instead of adding many new parameters per task.
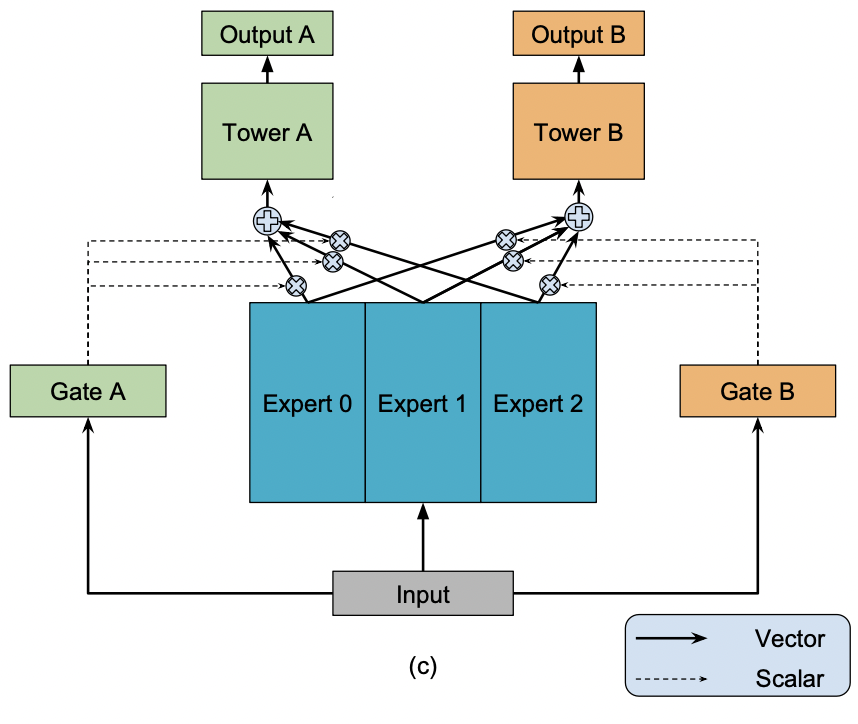
Given tasks, model consits of a shared-bottom network ( multi-layer perceptrons) which follows the input layer, and tower networks where .
The output of the shared bottom is the output of expert networks implemented as a single layer each. in the paper.
Each tower network (also a single layer) is associated with its own gate that determines how to weigh each expert network: where
Thus, the re-weighted shared bottom output for tower network is:
.
And the output of task is: .
Each gating network helps the model learn task-specific information.
Question: what loss function do they use? If task-specific they would most likely use binary cross-entropy for click through rate and mean squared error for watch time.