mistral-7B
Mistral.AI, October 2023
Leverages:
- grouped-query attention for faster inference and lower memory requirements during decoding (=> higher batch size => higher throughput)
- sliding window attention to handle sequences of arbitrary length
Outperforms Llama 2 13B and Llama 1 34B.
Sliding Window Attention
Each token can attend to at most 3 previous tokens instead of attending to every token in the sequence. At each attention layer, information can move forward by 3 tokens, thus tokens outside the window still influence next word prediction.
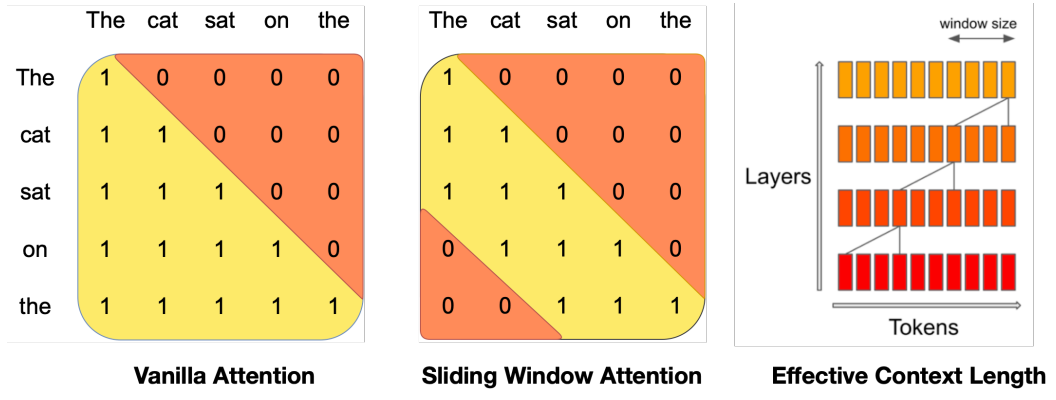
Considering the 32 layers, the theoretical attention span is 131k tokens.
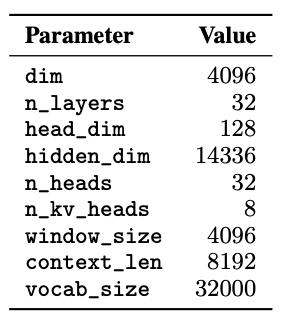
Attention layers parameters:
Rolling buffer cache
What is a buffer cache?
Anyways, thanks to the sliding window (say ), we only have to keep 4 keys and values in memory.
Pre-fill and chunking
Prompt is known in advance and can be put in the cache.
If prompt is too large, chunk it into chunks with same size as sliding window.