Source: Colah's blog post
Each layer creates a new representation by applying an affine transformation followed by a point-wise application of a monotone activation function.
When doing binary classification for example, the network disentangles the two classes so that they are linearly separable by a hyperplane in the final representation (hyperplane = subspace of dimension in a -dimensional space). The size of the dimensional space is given by the number of parameters in the network (all taken to be orthogonal directions).
Each layer stretches and squishes space but it never cuts, breaks, or folds it. Transformations that preserve topological properties are called homeomorphisms. They are bijections that are continuous functions both ways.
Why a simple feedforward layer is a homeomorphism:
Layers with inputs and outputs are homeomorphisms if the weight matrix is non-singular (if has rank / non-zero determinant, it is a bijective linear function with linear inverse). Moreover, translations (bias) are homeomorphisms as well as the non-linearity (if we are careful about the domain and range we consider). This is true for sigmoid, tanh and softplus but not ReLU (discontinuity at 0).
Example: topology and classification
Consider two dimensional dataset with two classes .
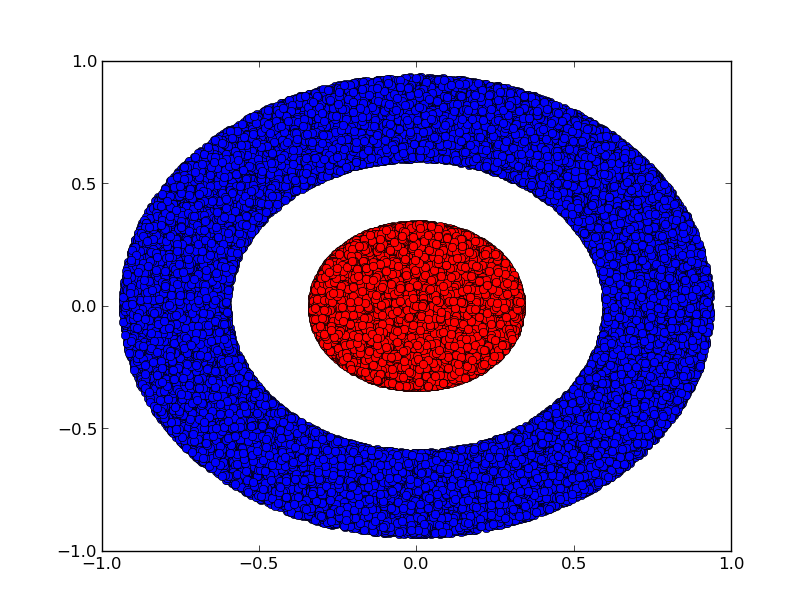
Claim: it is impossible for a neural network to classify this dataset without having a layer that has 3 or more hidden units, regardless of depth.
Proof: either each layer is a homeomorphism or the layer's weight matrix has determinant 0. Suppose it is a homeomorphism, then is still surrounded by and a line cannot separate them (if dimension 2 at most). Suppose it has determinant 0: the dataset gets collapsed on some zero volume hyperplane (since determinant of a matrix is the volume of the parallelogram defined by the column vectors of the matrix, in 2-dimensional case, an axis). Collapsing on any axis means points from and get mixed and cannot be linearly separated.
Why? Let a parallelepiped in be the set of points
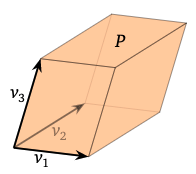
A parallelepiped has zero volume when it's flat i.e. it is squashed into a lower dimension, that is when are linearly dependent.
Moreover its volume is given by the absolute value of the determinant of the matrix with rows .
See https://textbooks.math.gatech.edu/ila/determinants-volumes.html.
Adding a third hidden unit, the problem becomes trivial:
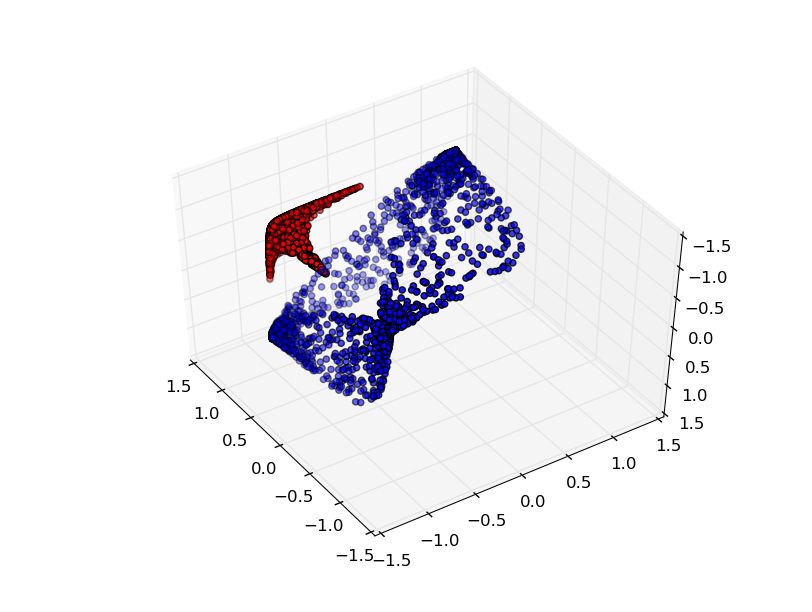
The Manifold Hypothesis
Manifold hypothesis is that natural data forms lower-dimensional manifolds in its embedding space. There are theoretical and experimental reasons to believe this is true. Task of a claassification algorithm is fundamentally to separate tangled manifolds (for example, separate the "cat" manifold from the "dog" manifold in the space of images ).
Links and homotopy
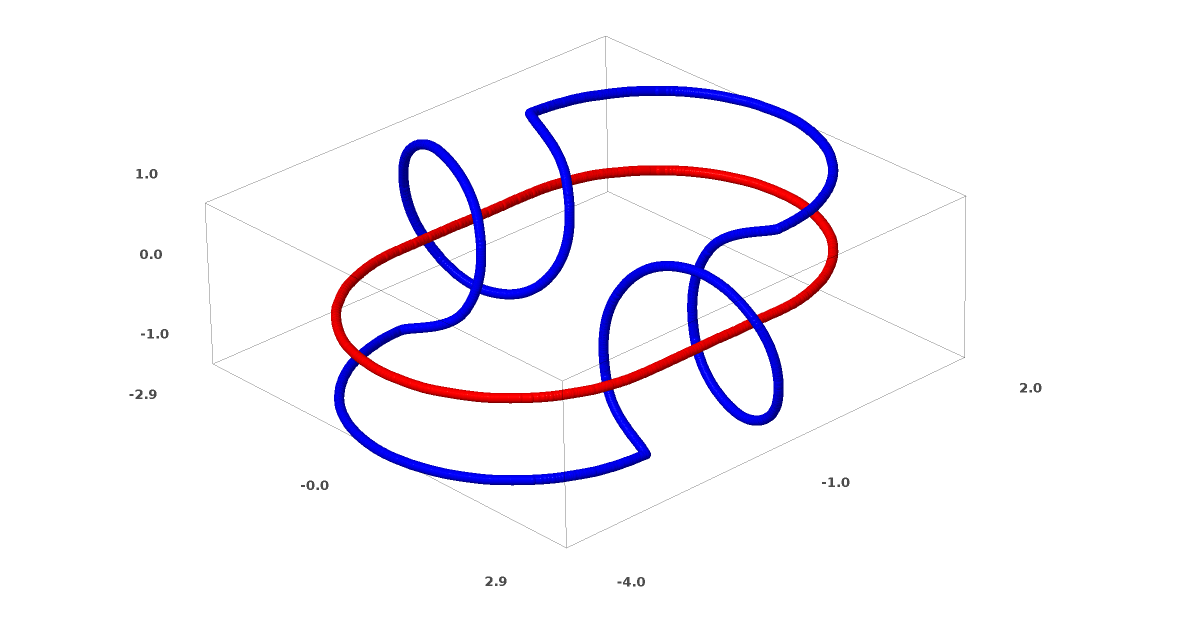
Consider two linked tori and .

Much like the previous dataset, this one cannot be separated without using dimensions (i.e. 4 in this case)
Links are studied in knot theory, an area of topology. Is a link an unlink (i.e. separable by continuous deformation) or not.
Example of an unlink:
An ambient isotopy is a procedure for untangling links. Formally, an ambient isotopy between manifolds and is a continuous function such that each is a homeomorphism from to its range. is the identity and maps to . continuously transitions from mapping to itself to mapping to .
Theorem: There is an ambient isotopy between the input and a network layer's representation if:
- a) isn't singular
- b) we are willing to permute the neurons in the hidden layer
- c) there is more than 1 hidden unit
Proof:
-
Need to have a positive determinant. We assume it is not zero and can flip the sign if it is negative by switching two hidden neurons (switching two rows of a matrix flips the sign of its determinant). The space of positive determinant matrices is path-connected (a path can be drawn between any two points in the space). Therefore we can connect the identity to : there exits a path (general linear group of degree , set of invertible matrices) such that and . We can continually transition from the identity function to the transformation with the function .
-
We can continually transition from the identity function to the translation (bias) with the function .
-
We can continually transition from the identity function to the pointwise use of with the function: .
Determining if knots are trivial is NP.
Links and knots are -dimensional manifolds but we need 4 dimensions to untangle them. All -dimensional manifolds can be untangled in dimensions.
The natural thing for a neural net to do is to pull the manifolds apart naively and stretch the parts that are tangled as thin as possible (can achieve high classification accuracy). This would present high gradients on the regions it is trying to stretch near-discontinuities. Contractive penalties, penalizing the derivatives of the layers at data points is a way to fight this.
Next steps
Read MIT's paper: Testing the Manifold Hypothesis
http://www.iro.umontreal.ca/~lisa/pointeurs/ICML2011_explicit_invariance.pdf
https://paperswithcode.com/paper/facenet-a-unified-embedding-for-face