Very popular in the past few months as it enabled fine-tuning of large language models with extreme parameter efficiency. You can now take GPT-3 and fine-tune it at low cost.
Takeaways
- instead of full fine-tuning, freeze entire pre-trained model weights and inject trainable rank-decomposition matrices into each transformer layer.
- 10,000x reduction in number of trainable parameters
- 3x reduction in GPU memory requirements
How did we fine-tune models before LoRA?
- fine-tune only some parameters. For example, freeze BERT, fine-tune only last linear projection
- learn an external module
Specifically for LLMs, 2 prominent strategies arose:
-
adapter layers:
-
2 layers inserted between the self-attention + feedforward layer and the residual connection
-
downside: has to be processed sequentially
-
-
prefix tuning:
-
insert trainable word embeddings as special tokens among the input tokens
-
downsides: reduces useful sequence size (because of the new tokens), optimizing the prompt is very hard and gains are not monotonically increasing with number of new tokens.
-
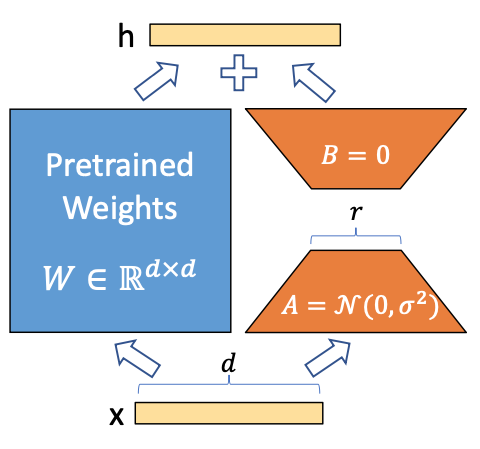
How LoRA works
Intuition: learned over-parameterized models reside on a low intrinsic dimension (linked to manifold hypothesis maybe?)
A pre-trained weight matrix is frozen. We update it with a low rank decomposition:
were , (and is very small). Onlyl and are trainable.
Initialization:
- init with random gaussian
- init with 0
Application to transformers
Transformers contain the following weight matrices:
- (query projection matrix), (key projection matrix), (value projection matrix), (output projection matrix)
- 2 in the MLP module (ignored here)
Some order of magnitude: with , only adapting the query and value projection matrices, we can reduce memory footprint of GPT-3 updates from 350GB to 35MB.
We can also switch between tasks easily (only need to swap LoRA weights).