Intro
- foundational language models ranging from 7B to 65B parameters.
Q: tf does foundational mean - publicly available datasets only
- LLaMA-13B outperforms GPT-3 (175B), LLaMA-65B is competitive with the best models Chinchilla-70B and PaLM-540B
- Can run on a single GPU
Few shot properties seem to be emerging from scaling model size.
They essentially train smaller models longer to make inference cheaper.
Inspired by the Chinchilla scaling laws.
Open source data
- english commoncrawl (67%): deduplication at line level, language identification to remove non-English pages, filters low quality content with n-gram language model. discarded pages that were not used as references on Wikipedia?
- C4 (15%): dedupliation and language identification
- Github: remove low quality files based on heuristics, removed boilerplate code (s.a. headers) with regular expressions, deduplicate resulting dataset at file level, with exact matches.
- Wikipedia (4.5%): covering 20 languages. Remove hyperlinks, comments, formatting boilerplate.
- Gutenberg and Books3 (4.5%): book corpara, deduplication at the book level
- ArXiv (2.5%): removed everything before first section, as well as bibliography.
- Stack Exchange (2%): removed html tags from text and sorted answers by score.
Tokenizer: byte-pair encoding (BPE) using SentencePiece. They split all numbers into individual digits, and fallback to bytes to decompose unknown UTF-8 characters (?).
Total number of tokens: 1.4T after tokenization. Each token used only once during training, except for Wikipedia and books, over which they perform 2 epochs.
Architecture
Difference with vanilla transformer:
- pre-normalization (gpt-3): to improve training stability, they normalize input of each transformer sub-layer instead of normalizing the output. Use RMSNorm normalizing function (normalize activation by root mean squared norm).
- SwiGLU activation function (PaLM): replace ReLU non-linearity by SwiGLU. Use a dimension of instead of as in PaLM.
SwiGLU = component wise product of two linear projections, one of which is first passed to a non-linear function (swish) to act as a gate.
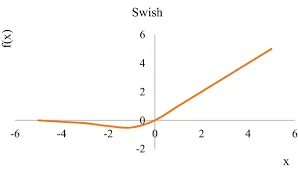
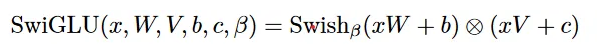
- Rotary Embeddings (GPTNeo): remove absolute positional embeddings and instead add a rotary positional embeddings (RoPE) at each layer.

Optimizer
AdamW with cosine learning rate schedule, weight decay of 0.1 and gradient clipping of 1.0 and 2000 warming steps.
Warm-up: A phase in the beginning of your neural network training where you start with a learning rate much smaller than your "initial" learning rate and then increase it over a few iterations or epochs until it reaches that "initial" learning rate.
Efficient implementation
- efficient implementation of causal multi-head attention: xformers library (not storing attention weights and not computing key/query scores that are masked)
- gradient checkpointing: saves activation that are expensive to compute, such that the outputs of linear layers. Manually implemented the backward function for the transformer layers instead of relying on PyTorch autograd. Also use model and sequence parallelism to reduce memory usage. They overlap computation of activations and communication between GPUs over the network (due to
all_reduceoperations) (???) - when training the 65B-parameter model, their code processes 380 tokens/sec/GPU on 2048 A100 GPU with 80GB of RAM. Training on 1.4T tokens takes 21 days.