Nobody cares about FLOPs (floating point operations per second), only thing that counts is where's my data?
Why?
Memory can feed data to CPU at 200 GB/sec = 25 GigaFP64/sec (FP64 = positives + negatives = 8 bytes) and CPU can compute around 2000 GFLOPs at fp64 precision.
compute intensity = FLOPs/Data Rate = 80 (how many operations per number loaded in memory so that CPU is not idle)
You want to compute intensity as low as you can (no algorithm can do 100 ops on a single number).
We should really be caring about memory bandwidth and latency
Why latency?
Example of DAXPY:
DAXPY: alpha X + Y = Z (DAXPY = double precision, saxpy=single precision)
Very important operation, processes have a dedicated instruction for this called FMA (fused multiply-add).
2 memory loads per element (x[i], y[i])
2 FLOPs: multiply & add
Most of the compiler's work is pipelining: making sure loads are done as early as possible to maximize number of operations data can be used in
- speed of light: 3.08e8 m/s
- computer clock frequency: 3e9 Hz (in 1 clock tick, light travels 100mm)
- speed of electricity in silicon: 6e7 m/s (in one clock tick, travels 20mm)
This means memory is 5 to 10 clock ticks away, but actually the problem is not the distance to the memory. The problem is the depth of the transistor pipeline.
E.g. Intel Xeon 8280
- memory bandwidth: 131 GB/sec
- memory latency of daxpy: 89 ns for 16 bytes (2*8 bytes values)
- memory efficiency =
- to keep memory bus busy we must do 729 iterations simultaneously
Concurrency: independent operations. See loop unrolling
Only option is threads (parallel). How many threads can we run? GPU has more than 1000x the threads available to CPU (200k vs 1k). Designed to having as many threads as possible (but higher latency). CPU cuts latency instead of having more threads
GPU keeps a large number of registers on each threads to keep data around at a low latency. Number of registers directly relate to the number of operations we can do (that's where the data is stored). GPU uses registers as buffer to hide latency. Register, L1 cache (1x time), L2 cache, (5x) (caches) and main memory (15x), off-chip (25x). Moving data across the PCIe bus (from off-chip to chip) takes the longest. NVlink (GPU to GPU) is much faster than PCIe.
GPU runs threads in groups of 32 (known as a wrap).
GPU can switch between wraps within a clock cycle (no context switch overhead). You can run warps back to back. This is called oversubscription.
GPU is optimized for throughput (designed for more work than it can handle at once)
CPU is a latency machine. Limited capacity so executes everything back to back as fast as possible.
CPU/GPU asynchrony is fundamental (they have to run at the same time)
However threads are rarely independent
E.g. 
E.g. training an image classification model
overlay image with grid. Operate on blocks within the grid. Blocks execute independently. GPU is oversubscribed with blocks. Many threads work together in each block for local data sharing (convolution operator): threads within a block run independently but may synchronize to exchange data.
-
Element-wise daxpy: data complexity O(N), compute complexity O(N) compute intensity scales as O(N/N) = O(1)
-
local convolution: O(N^2), O(N^2), O(1)
-
all-to-all (Fourier): O(N), O(N^2), O(N) (this boosts the required FLOPS and I can start challenging the computer's intensity number)
-
matrix multiplication (the one algo we really care about). arithmetic/compute intensity of matrix multiplication scales linearly
-
space complexity:
-
compute complexity:
-
compute intensity scales as , I improve my ability to keep FLOPs busy.
Sweet spot is the crossing point
More FLOPs require higher problem size otherwise memory is the bottleneck
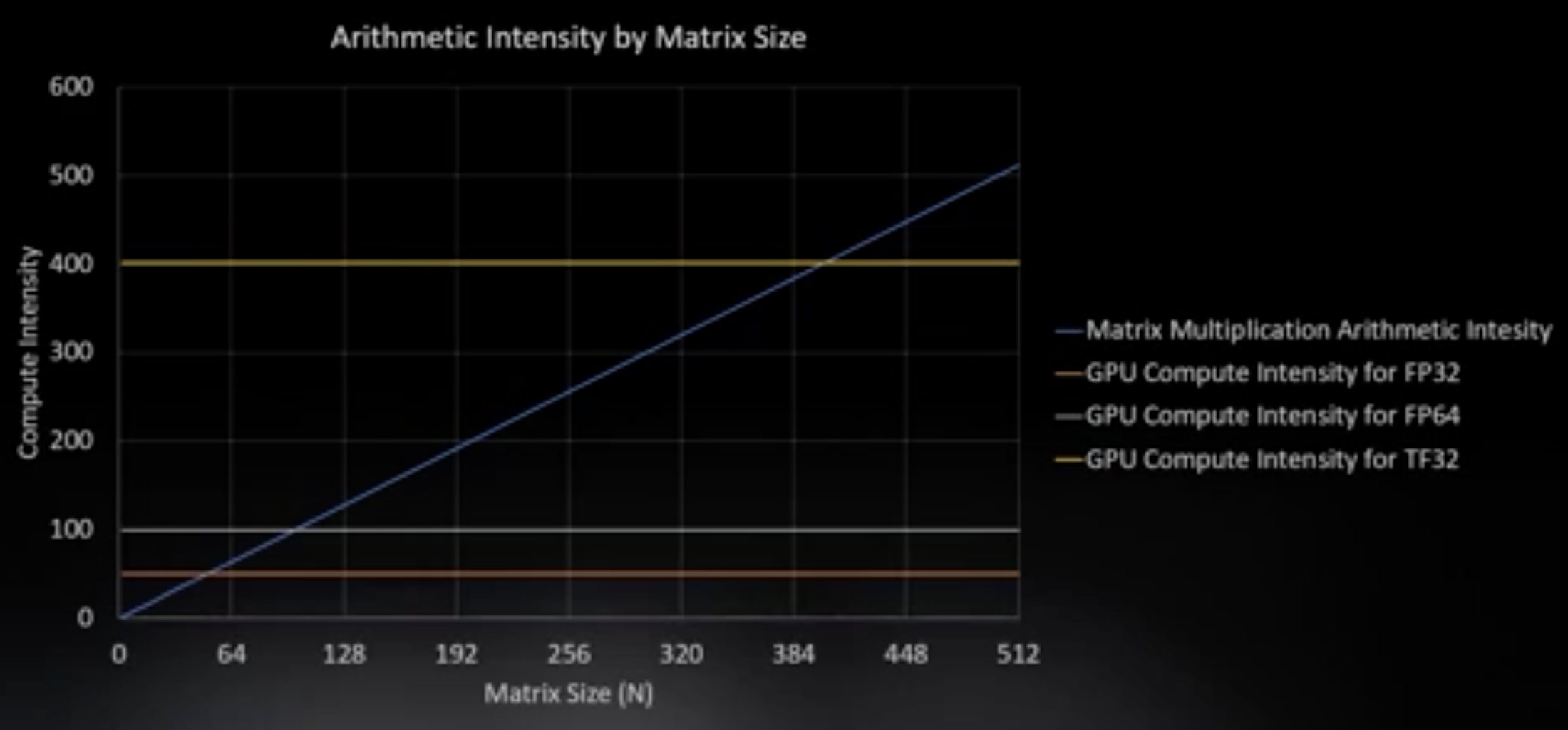
Tensorcore (TF32): matrix multiplication as one operation
This is where cache comes in: if I cache my data I can afford smaller matrices

Summary
- FLOPS don't matter as much as bandwidth because of compute intensity.
- bandwidth doesn't matter as much as latency
- to fix latency I need a lot of threads
- GPU is maximizes threads to hide the latency (throughput machine, needs oversubscription)
- GPU/CPU need to work together