Greedy Function Approximation - A Gradient Boosting Machine, Jerome Friedman (1999)
One of my favorite papers.
1. Function estimation
Given training sample , the goal is to obtain approximation of the function that minimizes the expected value of some loss function over the joint distribution of all values.
Frequently employed loss functions:
- squared-error (regression)
- absolute error (regression)
- negative binomial log-likelihood (classification, )
Common procedure is to restrict to be a member of a parameterized class of functions where is a finite set of parameters.
In this paper, we focus on "additive" expansions of the form:
Generic function is a simple function of the input variables, parameterized by
Such expansions are at the heart of many function approximation methods such as neural networks, radical basis functions, MARS, wavelets and support vector machines.
In this paper, each of the functions is a small regression tree. The parameters are the splitting variables, split locations, and the terminal node means of the individual trees.
1.1 Numerical optimization
Choosing a parameterized model changes the function optimization problem to one of parameter optimization:
The solution for the parameters is expressed in the form: where is an initial guess and are successive increments.
1.2 Steepest-descent
If we denote and
The step is taken to be where we perform line search along the steepest descent defined by negative gradient .
2. Numerical optimization in function space
Non-parametric approach: we consider evaluated at each point to be a parameter and seek to minimize:
In function space, there are an infinite number of such parameters, but in data sets, only a finite number . Following, the numerical optimization:
where is an initial guess and are incremental functions.
For steepest descent: with:
Among sufficient regularity that one can interchange differentiation and integration (see Leibniz Integral rule):
The multiplier is given by the line search:
3. Finite data
For a finite data sample, the expectation cannot be estimated accurately. Moreover, this approach would not ensure that the functions are adapted for unseen data points. We impose smoothness on the solution by assuming a parameterized form:
and minimize the data based estimate of expected loss:
If infeasible, one can try a greedy-stagewise approach. For :
and then:
Here, we don't readjust previously entered terms as in the stepwise approach.
- in signal processing, this stagewise strategy is called matching pursuit (squared-error loss). Functions are called basis functions and are taken from an over-complete wavelet-like dictionary
- in machine learning, it is called boosting and the loss is either the exponential loss criterion or the negative binomial log-likelihood. Function is called a weak learner or base learner and is a classification tree.
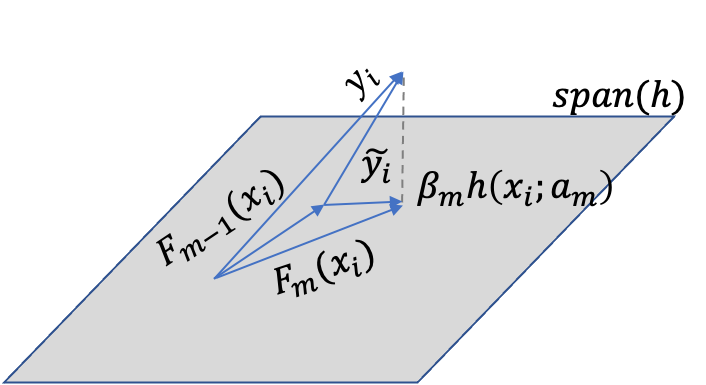
Given approximator , the function (i.e. after optimizing ) can be viewed the best greedy step towards the estimate of , under the constraint that the step direction be a member of the class of functions . It can thus be regarded as a steepest-descent step.
The unconstrained negative gradient:
gives the best steepest-descent step direction in the -dimensional data space at .
However, this gradient is only defined at data-points and cannot be generalized to other . We therefore choose that member of parameterized class that produces most parallel to (i.e. most highly correlated with it). It can be obtained by solving the least squares problem:
We then use as the negative gradient in line-search:
and:
Algorithm: Gradient Boost
\
For do:
4. Applications: additive modeling
4.1. Least-squares regression
and the derivative wrt F is the residuals . Therefore, are fitting the residuals and line search produces (we can thus skip the optimization step)
(using any base learner )
Question: How do we learn and at the same time? In least squares, the feature vector is fixed beforehand.
Answer: this is still theoretical. Here is any base learner; see the 4.3 section about using regression trees specifically.
4.2 Least-absolute-deviation (LAD) regression.
and .
Therefore is fit (by least-squares) to the sign of the current residuals and the line search becomes:
(using any base learner )
4.3. Regression trees
Base learner is a -terminal node regression tree. Each regression tree model has the additive form:
i.e. if then . Where the regions is a partition of .
The update becomes:
Where are regions defined by the terminal nodes at the th iteration. They are constructed to predict the pseudo-responses by least-squares.
We can view this as adding separate basis functions at each step. One can thus improve the quality of the fit by using the optimal coefficients for each of these separate basis functions:
Since the regions are disjoints, this reduces to:
(replace sum over data points to sum over regions)
Note:
In case of LAD regression, why not directly minimize: ?
Using squared-error loss to search for splits is much faster than mean-absolute-deviation. Why? (see CS289 lecture notes)
4.4 M-Regression
Attempts resistance to long-tailed error distributions and outliers while maintaining high efficiency for normally distributed errors. Consider the Huber loss function.
The transition point defines those residual values that are considered to be outliers, subject to absolute rather than squared error-loss. Common practice is to choose to be the -quantile of the distribution of , where controls the break-down point (fraction of observations that can be arbitrarily modified without seriously degrading the quality of the result). One can use as an approximation of :
With regression trees as base learners, we can do a separate update in each terminal node as seen in 4.3.
The solution to each update can be approximated by a single step of the standard iterative procedure (see Huber 1964), starting at the median of residuals:
The approximation is:
According to motivations underlying robust regression, this algorithm should have properties:
- similar to that of least-squares boosting for normally distributed errors
- similar to that of least-absolute-deviation regression with very long tailed distributions
- superior to both for error distributions with only moderately long tails
4.5 Two-class logistic regression and classification
Loss function is negative binomial log-likelihood: where (1/2 log odds).
With regression trees as base learners, we again use separate updates in each terminal node . There is no closed form solution to the minimization, thus we approximate it by a single Newton-Raphson step (see Friedman, Hastie, Tibshirani Additive logistic regression: a stistical view of boosting (2000)):
The log-odds can be inverted to get the probability estimates, which can be used for classification:
where is the cost of predicting when the truth is .
4.5.1 Influence trimming
Using the binomial log-likelihood, the empirical loss function:
If is very large, then will have almost no influence on the loss. This suggests that all observations for which is very large can be deleted from all computations of the -th iteration.
can be viewed as a measure of the influence of the -th iteration on the estimate
We can also use the second derivative of the loss with respect to as .
Influence trimming deletes all observations with -values less than where is the number of weights arranged in ascending order, whose sum equals times the total sum of weights (typical values are ).
90% to 95% of the observations are often deleted without sacrificing accuracy. Results in a corresponding reduction in computation by a factor 10 to 20.
4.6 Multi-class logistic regression and classification
where and .
Thus, -trees with -terminal nodes each are induced at each iteration to predict the corresponding current residuals for each class. Since the regions corresponding to different classes overlap, one cannot separate calculation within each region of each tree. Approximate solution with a single Newton-Raphson step using a diagonal approximation to the Hessian decomposes the problem into a separate calculation for each terminal node of each tree:
The final probability estimates at step can be used for classification:
For , this algorithm is equivalent to binary logistic regression.
Influence trimming for multi-class is implemented the same way as for two-class.
5. Regularization
For additive expansions, a natural regularization is the number of components . This places an implicit prior belief that "sparse" approximations involving fewer terms are likely to provide better predictions.
However, regularization through shrinkage provides superior results than restricting number of components (Copas 1983).
Simple shrinkage strategy is introducing learning rate :
There is a trade off between and (decreasing increases best value for , increasing increases computation time proportionately).
Misclassification error is not sensitive to over-fitting: misclassification error-rate decreases well after the logistic likelihood has reached its optimum. Error-rate depends only on the sign of , whereas the likelihood is affected by both magnitude and sign. Over-fitting degrades the quality of the estimate without affecting (and sometimes improving) the sign.
7. Tree boosting
- Meta-parameters of the GradientBoost procedure: and
- Meta-parameter of the base learner: number of terminal nodes .
Best choice for depends on the highest order of the dominant interactions among the variables.
Consider "ANOVA" expansion of a function:
- first sum is "main effects" component of . Reffered to as "additive" model because contributions of each , are added. Provides closest approximation to . More restrictive definition of "additive" model than the one provided at the beginning.
- second sum: two-variable "interaction effects"
- and so on...
Highest interaction order possible is limited by the number of input variables .
Purely additive approximations are also produced by the "naive"-Bayes method.
In boosting regression trees, the interaction order can be controlled by limiting the size of the individual trees induced at each iteration:
- a tree with terminal nodes produces a function with interaction order at most .
- Since boosting is additive, order of the entire approximation can be no larger than the largest among its individual components.
- Best tree size is governed by the effective interaction order of the target .
- As, this is usually unknown, becomes a meta-parameter to be estimated using a model selection criterion. It is unlikely that large trees would ever be necessary or desirable.
8. Interpretation
8.1 Relative importance of input variables
Does not strictly exist for piecewise constant approximations produced by decision trees. Breiman et al (1983) propose surrogate measure:
- summation over non-terminal nodes of the -terminal node tree
- is the splitting variable associated with node
- is the empirical improvement in squared error as a result of the split
- For a collection of decision trees : (generalization justified by heuristic arguments in the paper)
8.2 Partial dependence plots
Useful for visualizing functions of high dimensional arguments.
Let be a chosen "target" subset of size , of the input variables :
and the complement subset.
One can condition on particular values of and consider it as a function only of :
In general , depends on the particular values chosen for .
If this dependence is not too strong, the average function:
can represent a useful summary of the "partial dependence" of on .
is the marginal probability density of :
This complement marginal density can be estimated from the training data and finally:
For regression trees based on single-variable splits, the partial dependence of doesn't need reference to the data to be evaluated. For a specific set of values for , a weighted traversal is performed. At the root, a weight value of one is assigned. For each non-terminal node visited, if its split variable is in the target subset , the weight is not modified. If its in the complement subset , the weight is multiplied by the fraction of observations that went left or right respectively. When the traversal is complete, is the weighted average over the values of the terminal nodes.
When the dependence of on is additive or multiplicative (i.e. ), then provides a complete description of the nature of the variation of on the variable subset .
Therefore, subsets that group together influential inputs that hae complex (nonfactorable) interactions between them will provide the most reveling partial dependence plots.
As a diagnostic, we can compute , and compute the correlation of their sum/product with .
Interpretability of larger trees is questionable (too unstable).
10. Data Mining
Gradient Boosting is robust: it is invariant under all (strictly) monotone transformations of the individual input variables. E.g. using as the -th input variable yields the same result. No need for variable transformation. As a consequence, sensitivity to long tailed distribution and outliers is also eliminated (why? because you can make the spread between data points arbitrarily small by applying say the log function)
LAD- and M-regression are especially robust to outliers (absolute loss and Huber loss respectively).
Feature selection: trees are robust against the addition of irrelevant input variables. All tree based models handle missing values in a unified and elegant manner (Classification And Regression Trees, Breiman et al 1983) (WHY?, because if None, the variable is simply not considered for splitting?). No need to consider external imputation schemes.
Principal disadvantage of single tree models is inaccuracy due to piecewise-constant approximaions. This is solved by boosting (piecewise-constant approximations but granularity is much finer).