Parameterized Markov chain trained using variational inference to produce samples matching the data after finite time. Transitions of this chain are learned to reverse a diffusion process, which is a Markov chain that gradually adds noise to the data in the opposite direction of sampling until signal is destroyed.

Let be the parameterized reverse process. It's defined as Markov chain with learned Gaussian transitions starting at .
The forward process or diffusion process is fixed to a Markov chain that gradually adds Gaussian noise to the data according to a variance schedule :
In practice 's are linearly increasing constants. Therefore, the forward process has no learnable parameter.
Evidence lower bound
Goal is to maximize log-likelihood of original image under reverse process: .
Let's refer to as latent variable .
We can use importance sampling to estimate the log likelihood:
By Jensen's inequality:
(multiplying my and inverting the ineq. yields eq. 3 of the paper):
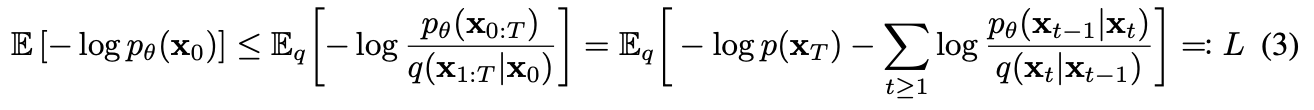
Paper then rewrites it as:
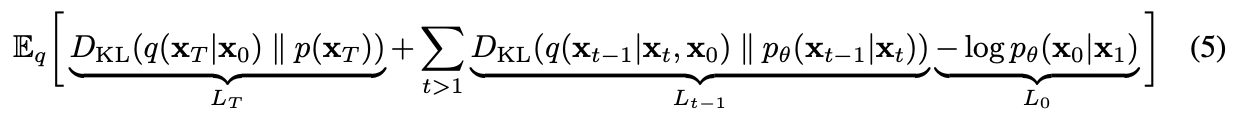
can be ignored since the forward process has no learnable parameters.
can be rewritten as:
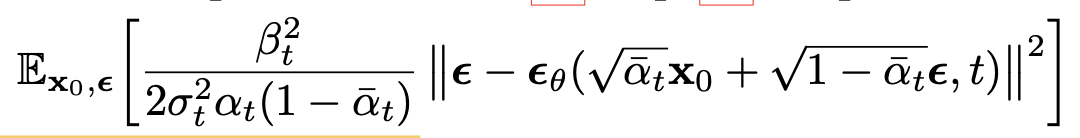
To obtain discrete log-likelihoods, the last term of the reverse process is set to an independent discrete decoder:
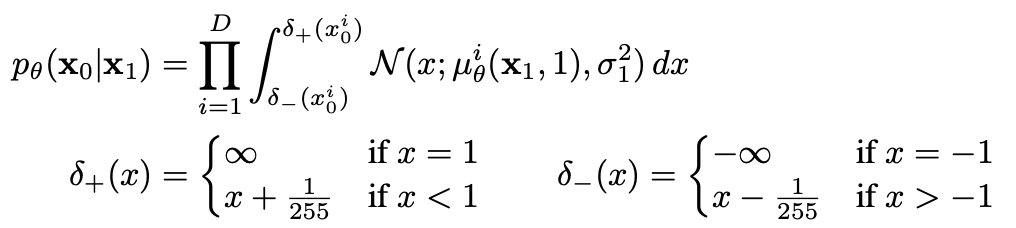
where is the data dimensionality. The reason is, since pixels are discrete and exact values are a zero probability event in continuous distributions, we integrate around the pixel's region (between and ).
At the end of sampling, we display noiselessly.
Q: "the variational bound is a lossless codelength (log-likelihood) of discrete data, without need of adding noise to the data or incorporating the Jacobian of the scaling operation into the log likelihood."
They found it beneficial to sample quality to discard the weighting term in the training objective. This down-weights loss terms corresponding to small (too easy to learn).

Experiment
Architecture
- Backbone of PixelCNN++ which is a U-Net based on a Wide ResNet
??? - replaced weight normalization with group normalization to make implementation simpler
- models use 4 feature map resolutions ( to ) and models use 6.
- two convolutional residual blocks per resolution level and self-attention blocks at the resolution between the convolutional blocks.
- Parameters are shared accross time steps and diffusion time is specified by adding the Transformer sinusoidal position embedding into each residual block.
- CIFAR10 model has 35.7 million params. LSUN and CelebA-HQ models have 114 million params.
Training
We used TPU v3-8 (similar to 8 V100 GPUs) for all experiments. Our CIFAR model trains at 21 steps per second at batch size 128 (10.6 hours to train to completion at 800k steps), and sampling a batch of 256 images takes 17 seconds. Our CelebA-HQ/LSUN (2562) models train at 2.2 steps per second at batch size 64, and sampling a batch of 128 images takes 300 seconds. We trained on CelebA-HQ for 0.5M steps, LSUN Bedroom for 2.4M steps, LSUN Cat for 1.8M steps, and LSUN Church for 1.2M steps. The larger LSUN Bedroom model was trained for 1.15M steps.
Hyperparameters
- . increasing linearly to (such that ).
- We set the dropout rate on CIFAR10 to 0.1 by sweeping over the values . Without dropout on CIFAR10, we obtained poorer samples reminiscent of the overfitting artifacts in an unregularized PixelCNN++
- We used random horizontal flips during training for CIFAR10; we tried training both with and without flips, and found flips to improve sample quality slightly. We also used random horizontal flips for all other datasets except LSUN Bedroom.
- We tried Adam and RMSProp early on in our experimentation process and chose the former. We left the hyperparameters to their standard values. We set the learning rate to 2 × 10−4 without any sweeping, and we lowered it to 2 × 10−5 for the 256 × 256 images, which seemed unstable to train with the larger learning rate.
- We set the batch size to 128 for CIFAR10 and 64 for larger images. We did not sweep over these values.
- We used exponential moving average on model parameters with a decay factor of 0.9999
Sample quality
Inception score
Used to assess the quality of images created by a generative image model. The score is calculated based on the output of a separate, pretrained Inceptionv3 image classification model applied to a sample of (typically around 30,000) images generated by the generative model. The Inception Score is maximized when the following conditions are true:
-
The entropy of the distribution of labels predicted by the Inceptionv3 model for the generated images is minimized. In other words, the classification model confidently predicts a single label for each image. Intuitively, this corresponds to the desideratum of generated images being "sharp" or "distinct".
-
The predictions of the classification model are evenly distributed across all possible labels. This corresponds to the desideratum that the output of the generative model is "diverse"

Fréchet Inception Distance (FID score)
Unlike the earlier inception score, which evaluates only the distribution of generated images, the FID compares the distribution of generated images with the distribution of a set of real images ("ground truth").
The FID metric was introduced in 2017, and is the current standard metric for assessing the quality of generative models as of 2020. It has been used to measure the quality of many recent models including the high-resolution StyleGAN1 and StyleGAN2 networks.
Rather than directly comparing images pixel by pixel (for example, as done by the L2 norm), the FID compares the mean and standard deviation of the deepest layer in Inception v3. These layers are closer to output nodes that correspond to real-world objects such as a specific breed of dog or an airplane, and further from the shallow layers near the input image. As a result, they tend to mimic human perception of similarity in images
