Overview
-
Collaborative filtering:
-
memory-based: e.g. item-based or user-based using nearest neighbor (limitations in dealing with sparse and large-scale data since it computes similarity scores)
-
model-based: e.g. latent factor models such as matrix factorization or neural networks
-
-
Implicit and explicit feedback
-
recommendation tasks:
-
rating prediction
-
top- recommendation (item ranking)
-
sequence-aware recommendation
-
click-through rate prediction: . Usually a binary classification problem (click or no click).
-
cold-start recommendation
-
Matrix factorization
Factorize the user-item interaction matrix (e.g. rating matrix) into a product of two lower-rank matrices, capturing the low-rank structure of the user-item interactions.
See this paragraph for details.
Evaluation metric: root mean squared error between observed and predicted interactions.
AutoRec: rating prediction with autoencoders
- Matrix factorization is a linear model and thus does not capture nonlinear relationships
- AutoRec differs from a traditional autoencoder in that, rather than learning the latent representations, it focuses on reconstructing the output layer.
- it uses a partially observed interaction matrix as input, aiming to reconstruct a completed rating matrix.
- Two variants: user-based and item-based
Item-based AutoRec
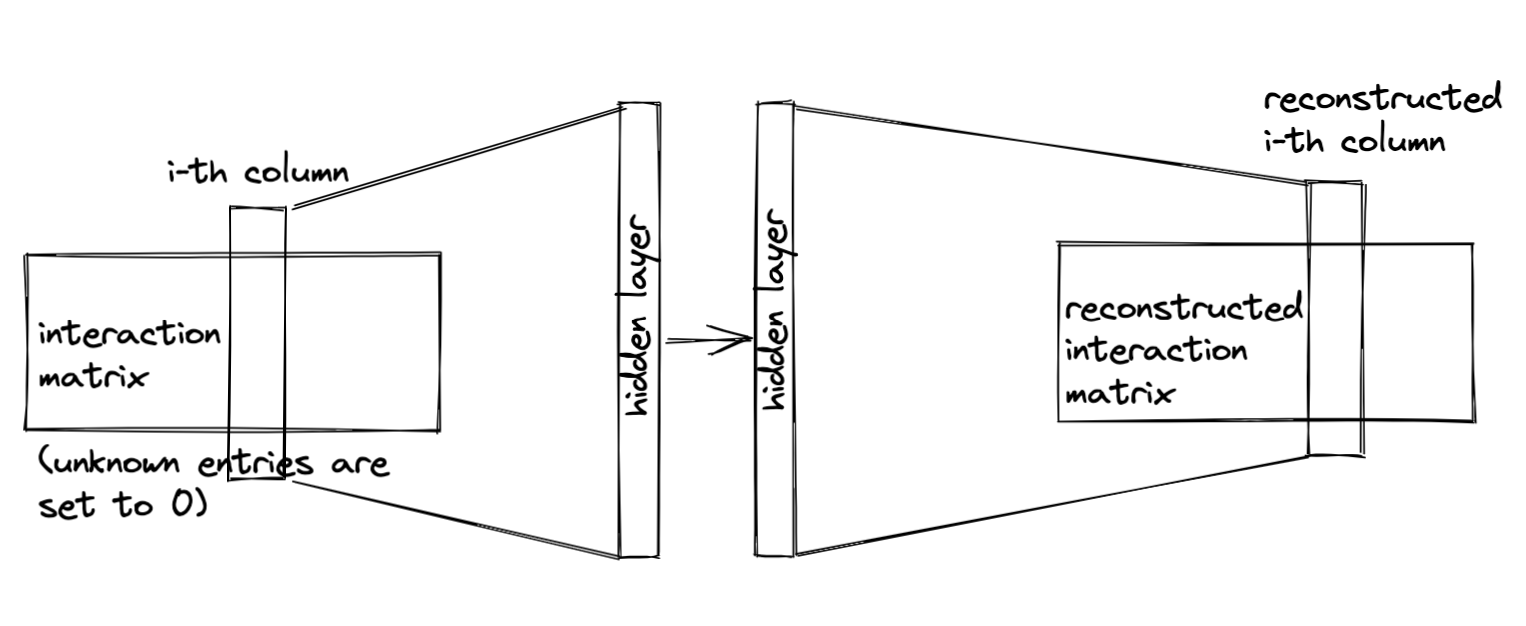
Reconstruction error: where is the ratings matrix
Personalized Ranking for Recommender Systems
- former methods only use explicit feedback (expensive to collect and most signals lie in implicit feedback)
- ratings might not be missing at random but because of users' preferences
Three types of ranking losses:
- pointwise approach: consider a single interaction at a time (e.g. matrix factorization and AutoRec are optimized with pointwise objectives)
- pairwise approach: consider a pair of items for each user and aim to approximate the optimal ordering for that pair. More suitable for ranking task. (see next sections: Bayesian Personalized Ranking loss and Hinge loss)
- Listwise approach: approximate the ordering of the entire list of items (e.g. direct optimizing the ranking measures such as normalized discounted cumulative gain). More complex and compute-intensive
Bayesian Personalized Ranking Loss
See original paper Bpr: bayesian personalized ranking from implicit feedback
Training data: tuples which represents that the user prefers item over item (both positive and negative pairs i.e. missing values, assumes user prefers positive item over all other non-observed items).
BPR aims to maximize the posterior probability of model parameters given desired personalized ranking for user :
Where is taken from the positive items and is taken from the negative items for user . is the predicted score of user to item .
Hinge Loss
Often used in Support Vector Machine classifiers.
where is the safety margin. It aims to push negative items away from positive items.
Neural Collaborative Filtering for Personalized Ranking
- implicit feedback (clicks, buys, watches)
NeuMF
- NeuMF (for neural matrix factorization, He et al, 2017) leverages non-linearity of neural nets to replace dot products in matrix factorization
- unlike the rating prediction task in [AutoRec](d2l_recommender_systems_course#AutoRec rating prediction with autoencoders), the model generates a ranked recommendation list to each user based on the implicit feedback
- fuses two subnetworks: generalized matrix factorization (GMF) and multi-layer perceptron (MLP)
- trained using pairwise ranking loss. Thus important to include negative sampling.
Generalized matrix factorization (GMF)
- is the -th row of (the user embeddings)
- is the -th row of (the item embeddings)
- is the number of users
- is the number of items
- is the number of latent dimensions
Multi-layer perceptron
- uses concatenation of user and item embeddings as input (not the same ones as the GMF layer) and passes it through a multi-layer perceptron
Final layer
is the prediction score of user for item :

Evaluation
Split dataset by time into training and test sets.
Hit rate at given cut-off (Hit @ r)
Where denotes the ranking of ground truth item of the user (the one that the user clicked on) in the predicted recommendation list (ideal ranking is 1).
Area under curve (AUC)
Proportion of times where the predicted rank of the ground truth item was better than that of irrelevant items.
Where
Sequence-Aware Recommender Systems
- in previous sections, we abstract the recommendation task as a matrix completion problem without considering users' short-term behaviors
- take sequentially-ordered user interaction logs into account
- modeling users' temporal behavioral patterns and discovering their interest drift
- point-level pattern: indicates impact of single item in historical sequence on target item
- union-level pattern: implies influences of several previous actions on subsequent target
CASER
Convolutional Sequence Embedding Recommendation
Let sequence denote the ordered sequence of items for user .
Suppose we take previous items into consideration. Embedding matrix that represents former interactions for time step can be contstructed: where is the -th row of item embeddings .
can be used to infer the transient interest of user at time-step and is used as input to the subsequent components.
is passed through an horizontal convolutional layer and a vertical convolutional layer in parallel. Their outputs are concatenated and passed into a fully-connected layer to get the final representation.
Where is another item embedding matrix, is the user embedding matrix for user's general tastes.
Model can be learned with BPR or Hinge loss.
Data generation process:

See also Session-based recommendations with RNNs
Feature-rich recommender systems
In addition to interaction data (sparse and noisy), integrate features of items, profiles of users and in which context the interaction occured.
Factorization Machines
- supervised algo used for classification, regression and ranking tasks
- generalization of linear regression and matrix factorization
- reminiscent of support vector machines with polynomial kernel
- can model -way variable interactions ( is polynoimal order, usually 2), fast optimization algo reduces polynomial computation time to linear complexity
2-way factorization machines
Let denote feature vectors of one sample, corresponding label (either real-valued label or class label). 2-way factorization machine defined as:
where is the global bias; denotes weights of -th variable; represents feature embeddings ( being dimensionality of latent factors)
First two terms correspond to linear regression and last term is an extension of matrix factorization.
Efficient optimization criterion
Naive evaluation leads to
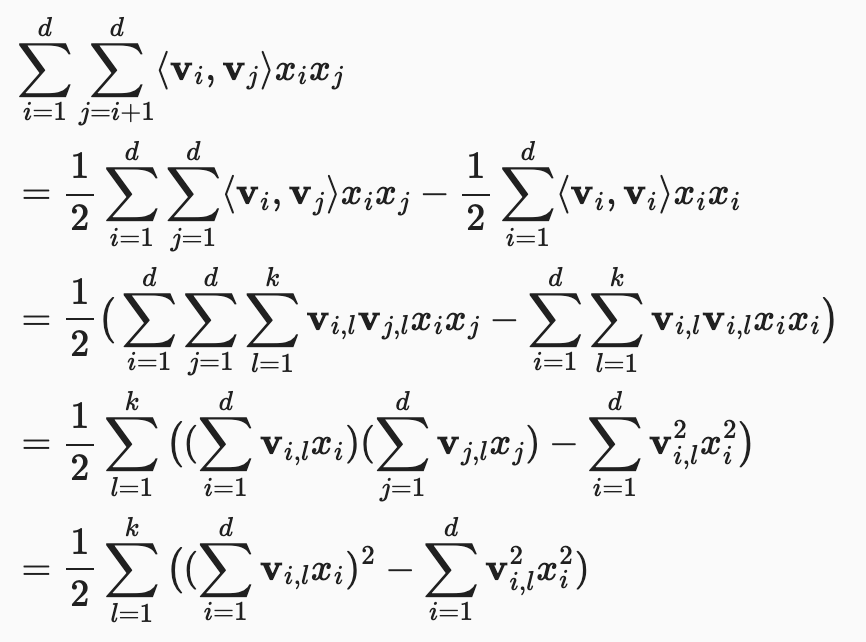
First line: total sum is twice the triangular sum - sum of diagonal.
Time complexity becomes linear: . Moreover, only non-zero elements need to be computed (efficient for sparse features).
Loss functions: MSE for regression, cross-entropy for classification, BPR loss for ranking.
Deep Factorization Machines
Factorization machines still combines interactions in a linear model. Higher order feature interactions (> 2) usually lead to numerical instability and high computational complexity.
Deep neural networks can learn sophisticated (nonlinear + higher order) feature interactions with rich feature representations.
DeepFM (Guo et al., 2017) has two components: factorization machine and multi-layer perceptron.
FM component's output is: (see previous section)
MLP component:
Let be the latent feature vector of feature .
Output is
Both outputs are combined in sigmoid function: .

See also Neural factorization machines for sparse predictive analytics