chip-huyen-real-time-machine-learning
Online prediction
Stage 1: batch prediction
- batch are precomputed at a certain interval (e.g. every hour for Twitter Ads)
- use cases: collaborative filtering, content-based recommendations
- big data processing has been dominated by batch systems like MapReduce and Spark
- batch prediction is largely a product of legacy systems
Limitations
See first post
- cold start problems: how to make recommendations to new visitors
Stage 2: online prediction with batch features
- collect user activity in real time and use pre-computed embeddings to generate session embeddings.
- goal is increasing conversion (e.g. converting first-time visitors to new users, click-through rates) and user retention
- challenges: inference latency, streaming infrastructure
- more efficient than generating prediction for all users (if only a subset of users log in daily)
Integrating session data into prediction service
- Streaming transport: Kafka / AWS Kinesis / GCP dataflow
- Streaming computation engine: Flink SQL, KSQL, Spark Streaming
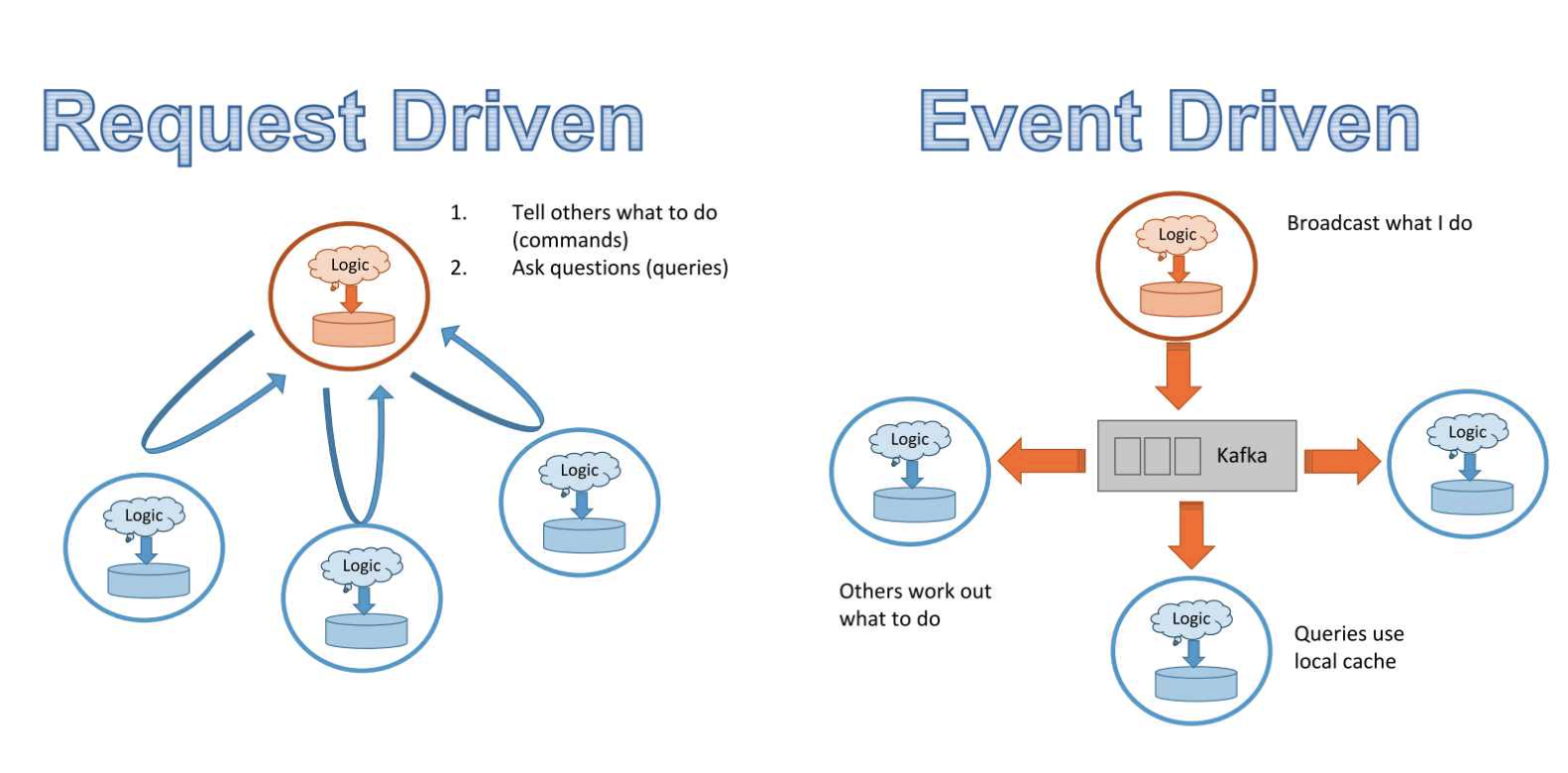
Request driven vs event driven architectures:
Streaming is getting quite popular in China as opposed to the US (see number of searches for Apache Flink)
Stage 3: online prediction with streaming features & batch features
-
e.g. Doordash trying to estimate delivery time:
-
batch features: mean preparation time of this restaurant in the past
-
streaming features: at this moment, how many other orders they have, how many delivery people are available
-
-
need a feature store for managing materialized features
-
need a model store for model lineage
(Contextual) Bandits vs A/B testing
- current industry standard for online model evaluation is A/B testing (routing traffic to each model and measuring which one works better at the end).
- Each model can be considered a slot machine whose payout (e.g. prediction accuracy) is unkown. Bandits allow you to maximize payout while minimizing wrong predictions shown to users.
- Bandits are more data-efficient than A/B testing
- In this experiment by Google’s Greg Rafferty, A/B test required over 630,000 samples to get a confidence interval of 95%, while a simple bandit algorithm (Thompson Sampling) determined that a model was 5% better than the other with less than 12,000 samples.
- See discussions on bandits at LinkedIn, Netflix, Facebook, Dropbox, and Stitch Fix. For a more theoretical view, see chapter 2 of the Reinforcement Learning book (Sutton & Barton, 2020).
Contextual bandits
- bandits determine the payout (e.g. prediction accuracy) of each model, contextual bandits determine the payout of each action. In the case of recommendations, an action is an item to show to users, and the payout is click probability.
- Contextual bandits achieve a balance between exploitation and exploration in the item showed.
- harder to implement since exploration strategy depends on model architecture
- see reports by Twitter and Google
Continual learning
Stage 1: adhoc, manual retraining
- query data warehouse, clean data, extract features, retrain model from scratch on both old and new data, export models in binary format, deploy model)
- feature / model / processing code was updated causing bugs
Stage 2: automated retraining
- script that automatically execute retraining process in batch, using Spark
- retraining schedules are based on gut feelings
- need a model store to automatically version and store all the code/artifacts needed to reproduce a model (e.g. S3 bucket, SageMaker (managed service), MLFlow (open-source))
- need a scheduler to automate workflow (CRON scheduler such as Airflow or Argo)
Stage 3: automated fine-tuning
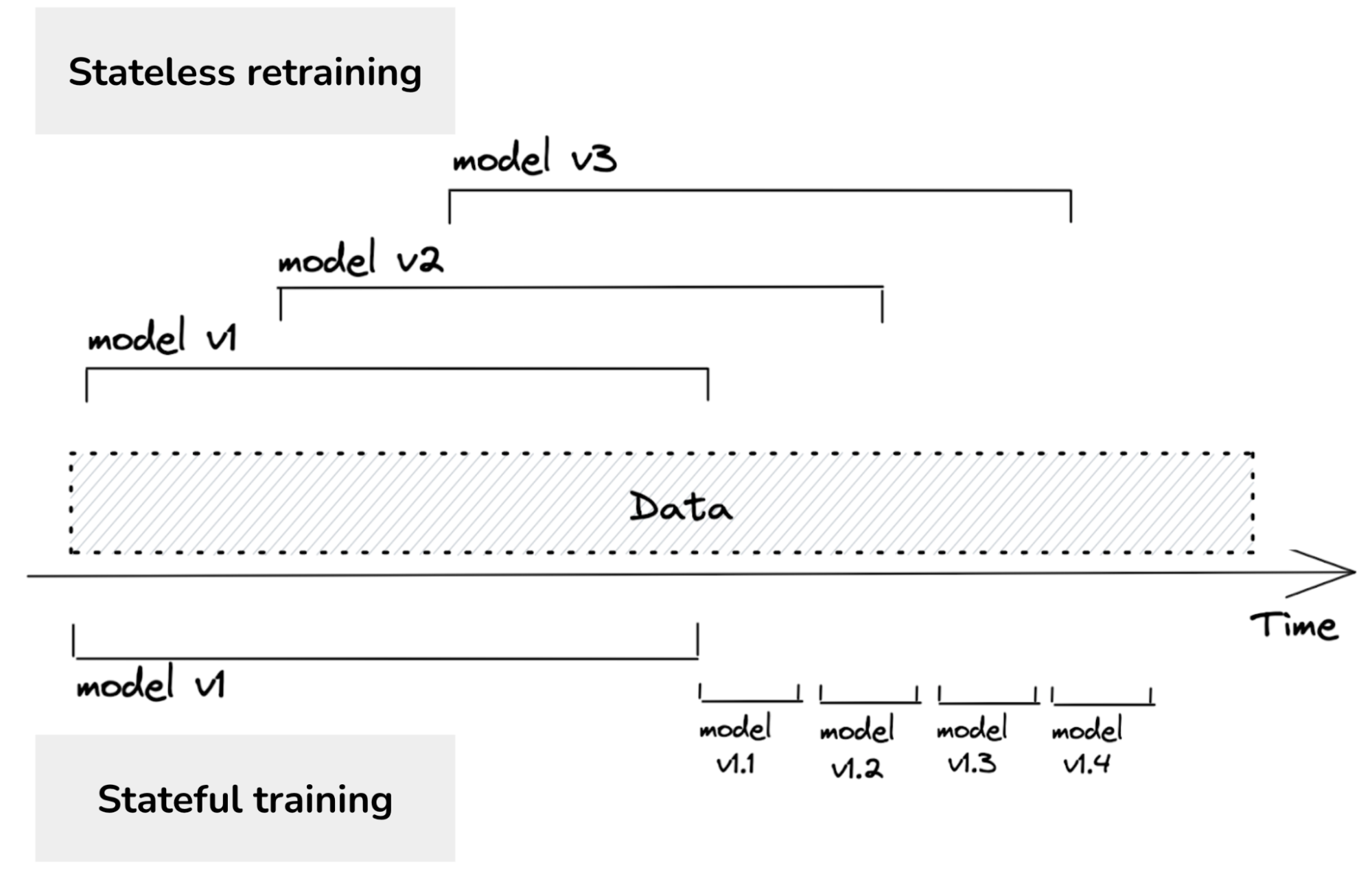
- data privacy: you only need to see the datapoint once, you can discard data after fine-tuning on it
- need model lineage (which model fine-tunes on which model)
Stage 4: continual learning
- continually update model whenever data distributions shift
- combine with edge deployment: ship base model with new device and model continually updates and adapts
Log and wait (feature reuse)
- when retraining, new data has already gone through your prediction service, which means features have already been extracted once for predictions.
- reuseing these extracted features for model updates both saves computation and allows for consistency between prediction and training (training-serving skew). This approach is known as log and wait
- See Faire's blog post