(2004) MapReduce is a programming model for processing large datasets on a cluster of commodity machines. Users specify a map function that processes a key/value pair to generate a set of intermediate key/value pairs, and a reduce function that merges all intermediate values associated with the same intermediate key.
motivation
code complexity:
- "the issues of how to parallelize the computation, distribute the data, and handle failures conspires to obscure the original simple computation with large amounts of complex code"
- The goal of the MapReduce library is to hide the messy details of parallelization, fault-tolerance, data-distribution and load balancing.
this paradigm has a wide range of applications: "most of our computations involve applying a map operation to each logical "record" in our input in order to compute a set of intermediate key / value pairs, and then applying a reduce operation to all the values that shared the same key."
programming model
- input: key / value pairs.
- Map function (written by the user): takes an input key value pair and emits a list of intermediate key / value pairs . The MapReduce library groups together all intermediate values associated with the same intermediate key and passes them to the Reduce function
- Reduce function (written by the user), takes and emits (the input keys and values are drawn from a different domain than the output keys and values. the intermediate keys and values are from the same domain as the output keys and values). It merges together these values to form a possibly smaller set of values. The intermediate values are supplied to the Reduce function via an iterator, which allows us to handle lists of values that are too large to fit in memory.
example applications
counting the number of occurrences of each word in a large collection of documents
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1"); // (w, "1") is the intermediate key/value pair
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = 0;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));
Reverse web-link graph
- the map function outputs
<target, source>pairs for each link to atargetURL found in a page namedsource - The reduce function concatenates the list of all source URLs associated with a given target URL and emits the pair:
<target, list(source)>
Architecture
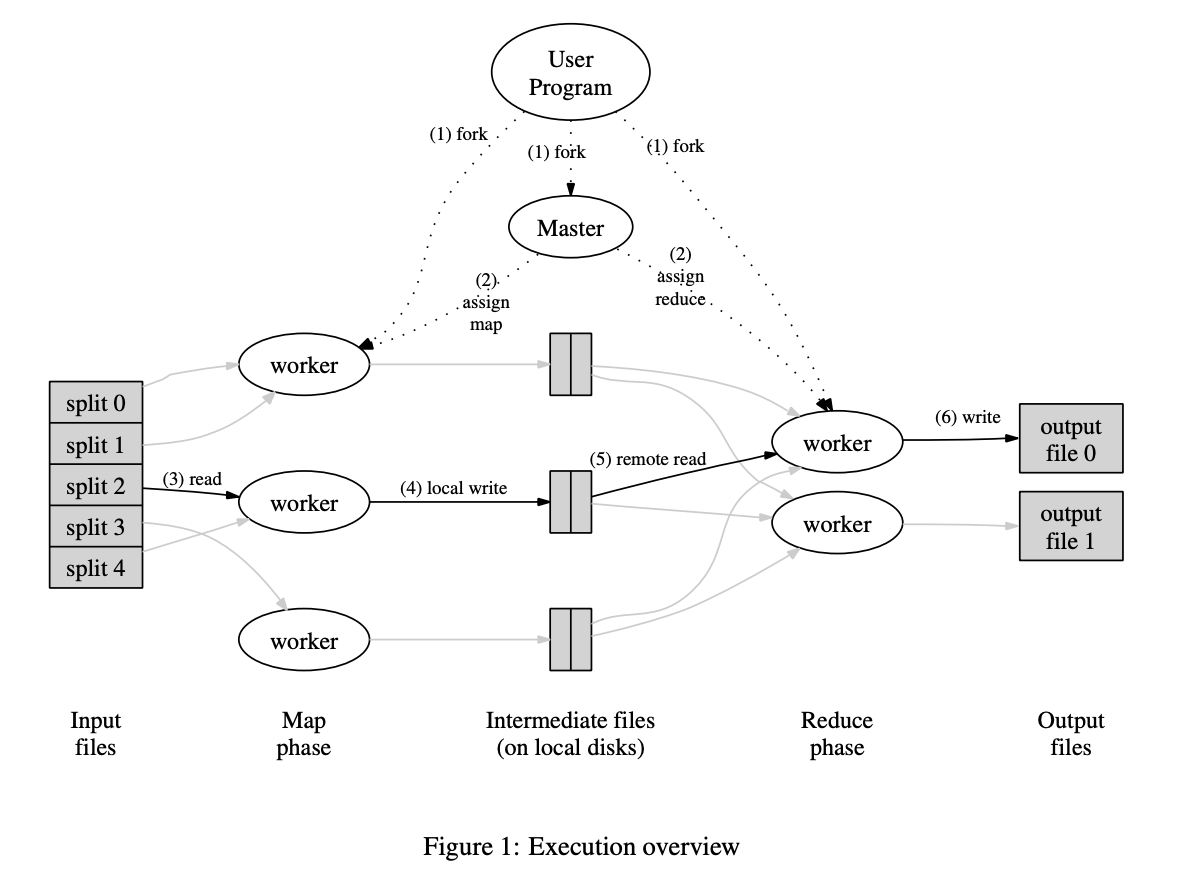
distributed calls
- the Map invocations are distributed across multiple machines by partitioning the input data.
split 0, 1, ..., M represents the partitioned input data. many copies of the program are started on a cluster of machines
- Reduce invocations are distributed: workers are assigned to intermediate partition key space using
hash(key) mod R - Thus, there are map and reduce tasks to assign. The master machine picks idle workers and assigns each one a map task or a reduce task.
- Ideally and should be much larger than the number of worker machines. Having each worker perform many different tasks improves dynamic load balancing and also speeds up recovery when a worker fails.
Note: reduce workers must wait on all map tasks to finish, because there is a dependency on having all intermediate keys (the same keys are processed together).
storing the outputs
the intermediate key / value pairs produced by Map are buffered in memory. Periodically, the buffered pairs are written to local disk, partitioned into regions by the partitioning function. The locations of these buffered pairs on the local disk are passed back to the master, who is responsible for forwarding these locations to the reduce workers.
reduce workers use remote procedure calls to read the buffered data from the local disks of the map workers.
when a reduce worker has read all intermediate data, it sorts it by the intermediate keys so that all occurrences of the same key are grouped together (same keys can't be in a different partition because they are passed through a hash). If the amount of data is too large to fit in memory, an external sort is used (spills sorted chunks to disk, external merge-sort, then process in stream).
the reduce worker iterates over the sorted intermediate data (written to disk) and for each unique intermediate key encountered, it passes the key and the corresponding set of intermediate values to the user's Reduce function (iterator). The output of the Reduce
function is appended to a final output file for this reduce partition.
After completion, the output of the MapReduce execution is available in the output files (one per reduce task). Typically, users pass these files as input to another MapReduce call.
locality: to save on network bandwidth (scarce resource), the master attempts to schedule a map task on a machine that already contains a replica of the corresponding input data.
fault tolerance
- worker failure: master pings every worker periodically. any map tasks completed by the worker are reset back to their initial idle state and therefore become eligible for scheduling on other workers. completed map tasks are re-executed on a failure because their output is stored on the local disk of the failed machine and is therefore inaccessible.
- master failure: write periodic checkpoint of the master data structures.
semantics
"when the user-supplied map and reduce operators are deterministic functions of their input values, our distributed implementation produces the same output as would have been produced by a non-faulting sequential execution of the entire program"
the fact that our semantics are equivalent to a sequential execution makes it very easy for programmers to reason about their program's behavior.
"The performance of the MapReduce library is good enough that we can keep conceptually unrelated computations separate, instead of mixing them together to avoid extra passes over the data."
compute environment
(2004 numbers):
-
Machines are typically dual-processor x86 processors running Linux, with 2-4 GB of memory per machine.
-
Commodity networking hardware is used - typically either 100 megabits / second or 1 gigabit / second at the machine level, but averaging considerably less in overall bisection bandwidth (the minimum aggregate bandwidth across a cut that divides the network into two equal-sized parts. This means you need to identify the "bottleneck" points in the network where the most data can flow through when the network is split.)
-
a cluster consists of hundreds or thousands of machines, and therefore machine failures are common.
-
storage is provided by disks attached directly to individual machines. A distributed file system is used to manage the data stored on these disks.
-
users submit jobs to a scheduling system. Each job consists of a set of tasks, and is mapped by the scheduler to a set of available machines within a cluster.